
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- AWS
- 볼륨 연결
- /etc/fstab 설정
- 테라폼 맥
- docker 상태
- Terrafrom
- EC2
- 볼륨추가
- ebs 재부팅
- /etc/fstab 뜻
- Mac Terraform
- AWS EBS
- 컨테이너 터미널 로그아웃
- 리눅스
- 텔레메트리란
- MFA 분실
- 컨테이너 터미널
- EBS 최적화
- 테라폼 자동완성
- ebs 마운트
- xfs_quota
- docker -i -t
- MFA 인증
- 테라폼 캐시
- 테라폼 설치
- 리눅스 시간대
- Authenticator
- EBS
- 디스크 성능테스트
- epxress-generator
- Today
- Total
I got IT
EKS 모니터링 본문
※ 해당 글은 CloudNet@ gasida 님의 EKS 스터디 내용을 참고하여 작성하였습니다.
실습 환경 배포
실습 환경 아키텍처
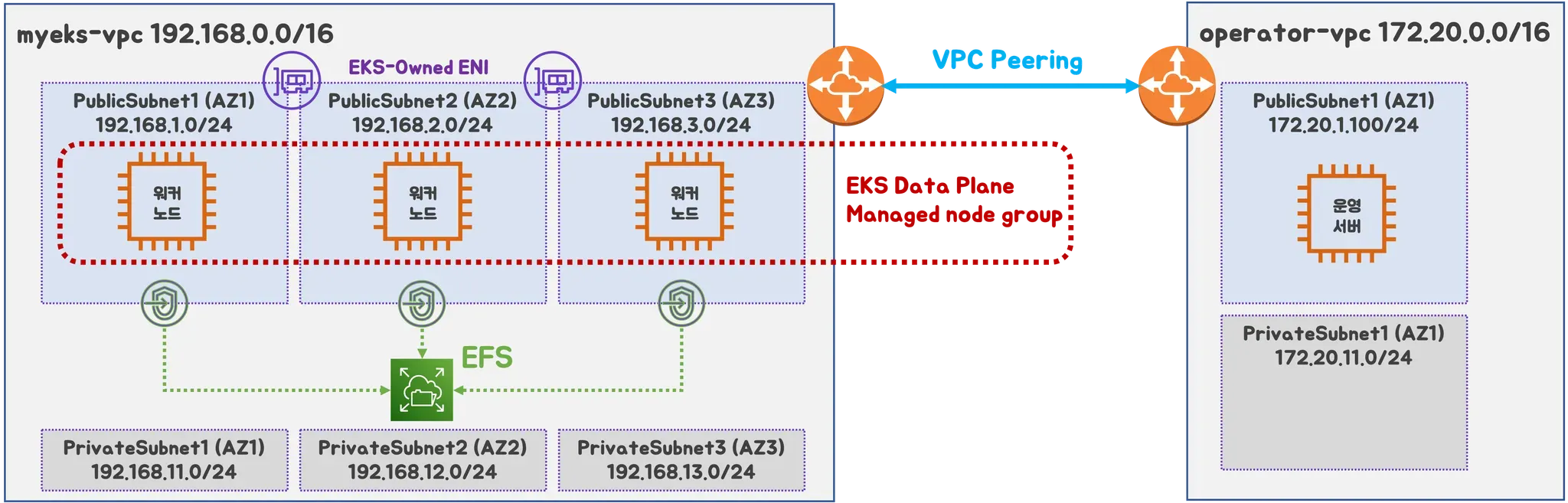
이번 실습 환경 구성 에서도 지난번과 마찬가지로 CloudFormation 을 활용할 것입니다.
아키텍처 특징
- EFS 사용하여 PV 설정
- 실무에서 흔히 사용하는 구조인 클러스터 운영용 서버를 퍼블릭에 프로비저닝(배스천)
- VPC Peering (상용 서비스의 경우 온프레미스 IDC 에서의 작업자 PC, DX 혹은 VPN 구성
- EKS optimized AMLX 2023 (최근에 나온 따끈따끈한 이미지 입니다. 자세한 내용은 다음 링크 참고🔗)
다음은 CloudFormation 에 쓰일 파라미터 입니다. 본인의 용도에 맞게 설정하도록 합니다.
- 운영 서버 관련
- KeyName : 운영서버 ec2에 SSH 접속을 위한 SSH 키페어 이름 지정
- MyIamUserAccessKeyID : 관리자 수준의 권한을 가진 IAM User의 액세스 키ID
- MyIamUserSecretAccessKey : 관리자 수준의 권한을 가진 IAM User의 시크릿 키ID ****
- SgIngressSshCidr : 운영서버 ec2에 SSH 접속 가능한 IP 입력 (집 공인IP/32 입력)
- MyInstanceType: 운영서버 EC2 인스턴스의 타입 (기본 t3.small) ⇒ 변경 가능
- LatestAmiId : 운영서버 EC2에 사용할 AMI는 아마존리눅스2 최신 버전 사용
- EKS Config
- ClusterBaseName : EKS 클러스터 이름이며, myeks 기본값 사용을 권장 → 이유: 실습 리소스 태그명과 실습 커멘드에서 사용
- KubernetesVersion : EKS 호환, 쿠버네티스 버전 (기본 v1.31, 실습은 1.31 버전 사용) ⇒ 변경 가능
- WorkerNodeInstanceType: 워커 노드 EC2 인스턴스의 타입 (기본 t3.medium) ⇒ 변경 가능
- WorkerNodeCount : 워커노드의 갯수를 입력 (기본 3대) ⇒ 변경 가능
- WorkerNodeVolumesize : 워커노드의 EBS 볼륨 크기 (기본 60GiB) ⇒ 변경 가능
- Region AZ : 리전과 가용영역을 지정, 실습 편의를 위해 기본값 그대로 사용
실습환경 배포
awscli를 사용할 것이기 때문에 awscli 설치와 관리자권한의 액세스키 config 설정을 해줍니다. (aws configure)
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/myeks-4week.yaml
# 변수 지정
CLUSTER_NAME=myeks
SSHKEYNAME=<SSH 키 페이 이름>
MYACCESSKEY=<IAM Uesr 액세스 키>
MYSECRETKEY=<IAM Uesr 시크릿 키>
WorkerNodeInstanceType=<워커 노드 인스턴스 타입> # 워커노드 인스턴스 타입 변경 가능
# CloudFormation 스택 배포
aws cloudformation deploy --template-file myeks-4week.yaml --stack-name $CLUSTER_NAME --parameter-overrides KeyName=$SSHKEYNAME SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=$MYACCESSKEY MyIamUserSecretAccessKey=$MYSECRETKEY ClusterBaseName=$CLUSTER_NAME WorkerNodeInstanceType=$WorkerNodeInstanceType --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 작업용 EC2 IP 출력
aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[0].OutputValue' --output text❗참고: 이전의 실습 환경 배포와는 달리, 이번에는 실습환경 구성을 좀더 편리하게 하기 위해 eksctl 명령어를 따로 실행하는 작업을 사용자가 직접하지 않고 ec2-userdata를 활용해 ec2 launch 시 EKS를 구성하도록 하였습니다.
AWSTemplateFormatVersion: '2010-09-09'
Metadata:
AWS::CloudFormation::Interface:
ParameterGroups:
- Label:
default: "<<<<< Deploy EC2 >>>>>"
Parameters:
- KeyName
- MyIamUserAccessKeyID
- MyIamUserSecretAccessKey
- SgIngressSshCidr
- MyInstanceType
- LatestAmiId
- Label:
default: "<<<<< EKS Config >>>>>"
Parameters:
- ClusterBaseName
- KubernetesVersion
- WorkerNodeInstanceType
- WorkerNodeCount
- WorkerNodeVolumesize
Parameters:
KeyName:
Description: Name of an existing EC2 KeyPair to enable SSH access to the instances. Linked to AWS Parameter
Type: AWS::EC2::KeyPair::KeyName
ConstraintDescription: must be the name of an existing EC2 KeyPair.
MyIamUserAccessKeyID:
Description: IAM User - AWS Access Key ID (won't be echoed)
Type: String
NoEcho: true
MyIamUserSecretAccessKey:
Description: IAM User - AWS Secret Access Key (won't be echoed)
Type: String
NoEcho: true
SgIngressSshCidr:
Description: The IP address range that can be used to communicate to the EC2 instances
Type: String
MinLength: '9'
MaxLength: '18'
Default: 0.0.0.0/0
AllowedPattern: (\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})/(\d{1,2})
ConstraintDescription: must be a valid IP CIDR range of the form x.x.x.x/x.
MyInstanceType:
Description: Enter t2.micro, t2.small, t2.medium, t3.micro, t3.small, t3.medium. Default is t2.micro.
Type: String
Default: t3.small
AllowedValues:
- t2.micro
- t2.small
- t2.medium
- t3.micro
- t3.small
- t3.medium
LatestAmiId:
Description: (DO NOT CHANGE)
Type: 'AWS::SSM::Parameter::Value<AWS::EC2::Image::Id>'
Default: '/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2'
AllowedValues:
- /aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2
ClusterBaseName:
Type: String
Default: myeks
AllowedPattern: "[a-zA-Z][-a-zA-Z0-9]*"
Description: must be a valid Allowed Pattern '[a-zA-Z][-a-zA-Z0-9]*'
ConstraintDescription: ClusterBaseName - must be a valid Allowed Pattern
KubernetesVersion:
Description: Enter Kubernetes Version, 1.23 ~ 1.26
Type: String
Default: 1.31
WorkerNodeInstanceType:
Description: Enter EC2 Instance Type. Default is t3.medium.
Type: String
Default: t3.medium
WorkerNodeCount:
Description: Worker Node Counts
Type: String
Default: 3
WorkerNodeVolumesize:
Description: Worker Node Volumes size
Type: String
Default: 60
OperatorBaseName:
Type: String
Default: operator
AllowedPattern: "[a-zA-Z][-a-zA-Z0-9]*"
Description: must be a valid Allowed Pattern '[a-zA-Z][-a-zA-Z0-9]*'
ConstraintDescription: operator - must be a valid Allowed Pattern
TargetRegion:
Type: String
Default: ap-northeast-2
AvailabilityZone1:
Type: String
Default: ap-northeast-2a
AvailabilityZone2:
Type: String
Default: ap-northeast-2b
AvailabilityZone3:
Type: String
Default: ap-northeast-2c
Vpc1Block:
Type: String
Default: 192.168.0.0/16
Vpc1PublicSubnet1Block:
Type: String
Default: 192.168.1.0/24
Vpc1PublicSubnet2Block:
Type: String
Default: 192.168.2.0/24
Vpc1PublicSubnet3Block:
Type: String
Default: 192.168.3.0/24
Vpc1PrivateSubnet1Block:
Type: String
Default: 192.168.11.0/24
Vpc1PrivateSubnet2Block:
Type: String
Default: 192.168.12.0/24
Vpc1PrivateSubnet3Block:
Type: String
Default: 192.168.13.0/24
Vpc2Block:
Type: String
Default: 172.20.0.0/16
Vpc2PublicSubnet1Block:
Type: String
Default: 172.20.1.0/24
Vpc2PrivateSubnet1Block:
Type: String
Default: 172.20.11.0/24
Resources:
# VPC1
EksVPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: !Ref Vpc1Block
EnableDnsSupport: true
EnableDnsHostnames: true
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-VPC
# Vpc1PublicSubnets
Vpc1PublicSubnet1:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone1
CidrBlock: !Ref Vpc1PublicSubnet1Block
VpcId: !Ref EksVPC
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PublicSubnet1
- Key: kubernetes.io/role/elb
Value: 1
Vpc1PublicSubnet2:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone2
CidrBlock: !Ref Vpc1PublicSubnet2Block
VpcId: !Ref EksVPC
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PublicSubnet2
- Key: kubernetes.io/role/elb
Value: 1
Vpc1PublicSubnet3:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone3
CidrBlock: !Ref Vpc1PublicSubnet3Block
VpcId: !Ref EksVPC
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PublicSubnet3
- Key: kubernetes.io/role/elb
Value: 1
Vpc1InternetGateway:
Type: AWS::EC2::InternetGateway
Vpc1GatewayAttachment:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
InternetGatewayId: !Ref Vpc1InternetGateway
VpcId: !Ref EksVPC
Vpc1PublicSubnetRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref EksVPC
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PublicSubnetRouteTable
Vpc1PublicSubnetRoute:
Type: AWS::EC2::Route
Properties:
RouteTableId: !Ref Vpc1PublicSubnetRouteTable
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref Vpc1InternetGateway
Vpc1PublicSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc1PublicSubnet1
RouteTableId: !Ref Vpc1PublicSubnetRouteTable
Vpc1PublicSubnet2RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc1PublicSubnet2
RouteTableId: !Ref Vpc1PublicSubnetRouteTable
Vpc1PublicSubnet3RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc1PublicSubnet3
RouteTableId: !Ref Vpc1PublicSubnetRouteTable
# Vpc1PrivateSubnets
Vpc1PrivateSubnet1:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone1
CidrBlock: !Ref Vpc1PrivateSubnet1Block
VpcId: !Ref EksVPC
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PrivateSubnet1
- Key: kubernetes.io/role/internal-elb
Value: 1
Vpc1PrivateSubnet2:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone2
CidrBlock: !Ref Vpc1PrivateSubnet2Block
VpcId: !Ref EksVPC
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PrivateSubnet2
- Key: kubernetes.io/role/internal-elb
Value: 1
Vpc1PrivateSubnet3:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone3
CidrBlock: !Ref Vpc1PrivateSubnet3Block
VpcId: !Ref EksVPC
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PrivateSubnet3
- Key: kubernetes.io/role/internal-elb
Value: 1
Vpc1PrivateSubnetRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref EksVPC
Tags:
- Key: Name
Value: !Sub ${ClusterBaseName}-Vpc1PrivateSubnetRouteTable
Vpc1PrivateSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc1PrivateSubnet1
RouteTableId: !Ref Vpc1PrivateSubnetRouteTable
Vpc1PrivateSubnet2RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc1PrivateSubnet2
RouteTableId: !Ref Vpc1PrivateSubnetRouteTable
Vpc1PrivateSubnet3RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc1PrivateSubnet3
RouteTableId: !Ref Vpc1PrivateSubnetRouteTable
# VPC2
OpsVPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: !Ref Vpc2Block
EnableDnsSupport: true
EnableDnsHostnames: true
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-VPC
# Vpc2PublicSubnets
Vpc2PublicSubnet1:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone1
CidrBlock: !Ref Vpc2PublicSubnet1Block
VpcId: !Ref OpsVPC
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-Vpc2PublicSubnet1
Vpc2InternetGateway:
Type: AWS::EC2::InternetGateway
Vpc2GatewayAttachment:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
InternetGatewayId: !Ref Vpc2InternetGateway
VpcId: !Ref OpsVPC
Vpc2PublicSubnetRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref OpsVPC
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-Vpc2PublicSubnetRouteTable
Vpc2PublicSubnetRoute:
Type: AWS::EC2::Route
Properties:
RouteTableId: !Ref Vpc2PublicSubnetRouteTable
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref Vpc2InternetGateway
Vpc2PublicSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc2PublicSubnet1
RouteTableId: !Ref Vpc2PublicSubnetRouteTable
# Vpc2PrivateSubnets
Vpc2PrivateSubnet1:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone: !Ref AvailabilityZone1
CidrBlock: !Ref Vpc2PrivateSubnet1Block
VpcId: !Ref OpsVPC
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-Vpc2PrivateSubnet1
Vpc2PrivateSubnetRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref OpsVPC
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-Vpc2PrivateSubnetRouteTable
Vpc2PrivateSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref Vpc2PrivateSubnet1
RouteTableId: !Ref Vpc2PrivateSubnetRouteTable
# VPC Peering
VPCPeering:
Type: AWS::EC2::VPCPeeringConnection
Properties:
VpcId: !Ref EksVPC
PeerVpcId: !Ref OpsVPC
Tags:
- Key: Name
Value: VPCPeering-EksVPC-OpsVPC
PeeringRoute1:
Type: AWS::EC2::Route
Properties:
DestinationCidrBlock: 172.20.0.0/16
RouteTableId: !Ref Vpc1PublicSubnetRouteTable
VpcPeeringConnectionId: !Ref VPCPeering
PeeringRoute2:
Type: AWS::EC2::Route
Properties:
DestinationCidrBlock: 192.168.0.0/16
RouteTableId: !Ref Vpc2PublicSubnetRouteTable
VpcPeeringConnectionId: !Ref VPCPeering
# EFS
EFSSG:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId: !Ref EksVPC
GroupDescription: EFS Security Group
Tags:
- Key : Name
Value : !Sub ${ClusterBaseName}-EFS
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: '2049'
ToPort: '2049'
CidrIp: !Ref Vpc1Block
- IpProtocol: tcp
FromPort: '2049'
ToPort: '2049'
CidrIp: 172.20.1.100/32
ElasticFileSystem:
Type: AWS::EFS::FileSystem
Properties:
FileSystemTags:
- Key: Name
Value: !Sub ${ClusterBaseName}-EFS
ElasticFileSystemMountTarget0:
Type: AWS::EFS::MountTarget
Properties:
FileSystemId: !Ref ElasticFileSystem
SecurityGroups:
- !Ref EFSSG
SubnetId: !Ref Vpc1PublicSubnet1
ElasticFileSystemMountTarget1:
Type: AWS::EFS::MountTarget
Properties:
FileSystemId: !Ref ElasticFileSystem
SecurityGroups:
- !Ref EFSSG
SubnetId: !Ref Vpc1PublicSubnet2
ElasticFileSystemMountTarget2:
Type: AWS::EFS::MountTarget
Properties:
FileSystemId: !Ref ElasticFileSystem
SecurityGroups:
- !Ref EFSSG
SubnetId: !Ref Vpc1PublicSubnet3
# OPS-Host
OPSSG:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Operator-host Security Group
VpcId: !Ref OpsVPC
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-HOST-SG
SecurityGroupIngress:
- IpProtocol: '-1'
CidrIp: !Ref SgIngressSshCidr
- IpProtocol: '-1'
CidrIp: 192.168.0.0/16
OPSEC2:
Type: AWS::EC2::Instance
Properties:
InstanceType: !Ref MyInstanceType
ImageId: !Ref LatestAmiId
KeyName: !Ref KeyName
Tags:
- Key: Name
Value: !Sub ${OperatorBaseName}-host
NetworkInterfaces:
- DeviceIndex: 0
SubnetId: !Ref Vpc2PublicSubnet1
GroupSet:
- !Ref OPSSG
AssociatePublicIpAddress: true
PrivateIpAddress: 172.20.1.100
BlockDeviceMappings:
- DeviceName: /dev/xvda
Ebs:
VolumeType: gp3
VolumeSize: 30
DeleteOnTermination: true
UserData:
Fn::Base64:
!Sub |
#!/bin/bash
hostnamectl --static set-hostname "${OperatorBaseName}-host"
# Config convenience
echo 'alias vi=vim' >> /etc/profile
echo "sudo su -" >> /home/ec2-user/.bashrc
sed -i "s/UTC/Asia\/Seoul/g" /etc/sysconfig/clock
ln -sf /usr/share/zoneinfo/Asia/Seoul /etc/localtime
# Install Packages
yum -y install tree jq git htop amazon-efs-utils
# Install kubectl & helm
cd /root
curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/1.31.2/2024-11-15/bin/linux/amd64/kubectl
install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
curl -s https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
# Install eksctl
curl -sL "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_Linux_amd64.tar.gz" | tar xz -C /tmp
mv /tmp/eksctl /usr/local/bin
# Install aws cli v2
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip >/dev/null 2>&1
./aws/install
complete -C '/usr/local/bin/aws_completer' aws
echo 'export AWS_PAGER=""' >>/etc/profile
# Install kube-ps1
echo 'source <(kubectl completion bash)' >> /root/.bashrc
echo 'alias k=kubectl' >> /root/.bashrc
echo 'complete -F __start_kubectl k' >> /root/.bashrc
git clone https://github.com/jonmosco/kube-ps1.git /root/kube-ps1
cat <<"EOT" >> /root/.bashrc
source /root/kube-ps1/kube-ps1.sh
KUBE_PS1_SYMBOL_ENABLE=false
function get_cluster_short() {
echo "$1" | cut -d . -f1
}
KUBE_PS1_CLUSTER_FUNCTION=get_cluster_short
KUBE_PS1_SUFFIX=') '
PS1='$(kube_ps1)'$PS1
EOT
# IAM User Credentials
export AWS_ACCESS_KEY_ID=${MyIamUserAccessKeyID}
export AWS_SECRET_ACCESS_KEY=${MyIamUserSecretAccessKey}
export AWS_DEFAULT_REGION=${AWS::Region}
export ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' --output text)
export SSHKEYNAME=${KeyName}
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID" >> /etc/profile
echo "export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY" >> /etc/profile
echo "export AWS_DEFAULT_REGION=$AWS_DEFAULT_REGION" >> /etc/profile
echo "export ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' --output text)" >> /etc/profile
echo "export SSHKEYNAME=${KeyName}" >> /etc/profile
# CLUSTER_NAME
export CLUSTER_NAME=${ClusterBaseName}
echo "export CLUSTER_NAME=$CLUSTER_NAME" >> /etc/profile
# K8S Version
export KUBERNETES_VERSION=${KubernetesVersion}
echo "export KUBERNETES_VERSION=$KUBERNETES_VERSION" >> /etc/profile
# VPC & Subnet
export VPCID=$(aws ec2 describe-vpcs --filters "Name=tag:Name,Values=$CLUSTER_NAME-VPC" --query 'Vpcs[*].VpcId' --output text)
echo "export VPCID=$VPCID" >> /etc/profile
export PubSubnet1=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet1" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet2=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet2" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet3=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet3" --query "Subnets[0].[SubnetId]" --output text)
echo "export PubSubnet1=$PubSubnet1" >> /etc/profile
echo "export PubSubnet2=$PubSubnet2" >> /etc/profile
echo "export PubSubnet3=$PubSubnet3" >> /etc/profile
# Create EKS Cluster & Nodegroup
cat << EOF > $CLUSTER_NAME.yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: $CLUSTER_NAME
region: $AWS_DEFAULT_REGION
version: "$KUBERNETES_VERSION"
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: aws-load-balancer-controller
namespace: kube-system
wellKnownPolicies:
awsLoadBalancerController: true
vpc:
cidr: ${Vpc1Block}
clusterEndpoints:
privateAccess: true
publicAccess: true
id: $VPCID
subnets:
public:
ap-northeast-2a:
az: ap-northeast-2a
cidr: ${Vpc1PublicSubnet1Block}
id: $PubSubnet1
ap-northeast-2b:
az: ap-northeast-2b
cidr: ${Vpc1PublicSubnet2Block}
id: $PubSubnet2
ap-northeast-2c:
az: ap-northeast-2c
cidr: ${Vpc1PublicSubnet3Block}
id: $PubSubnet3
addons:
- name: vpc-cni # no version is specified so it deploys the default version
version: latest # auto discovers the latest available
attachPolicyARNs: # attach IAM policies to the add-on's service account
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
configurationValues: |-
enableNetworkPolicy: "true"
- name: kube-proxy
version: latest
- name: coredns
version: latest
- name: metrics-server
version: latest
- name: aws-ebs-csi-driver
version: latest
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- amiFamily: AmazonLinux2023
desiredCapacity: ${WorkerNodeCount}
iam:
withAddonPolicies:
certManager: true
externalDNS: true
instanceType: ${WorkerNodeInstanceType}
preBootstrapCommands:
# install additional packages
- "dnf install nvme-cli links tree tcpdump sysstat ipvsadm ipset bind-utils htop -y"
labels:
alpha.eksctl.io/cluster-name: $CLUSTER_NAME
alpha.eksctl.io/nodegroup-name: ng1
maxPodsPerNode: 60
maxSize: 3
minSize: 3
name: ng1
ssh:
allow: true
publicKeyName: $SSHKEYNAME
tags:
alpha.eksctl.io/nodegroup-name: ng1
alpha.eksctl.io/nodegroup-type: managed
volumeIOPS: 3000
volumeSize: ${WorkerNodeVolumesize}
volumeThroughput: 125
volumeType: gp3
EOF
nohup eksctl create cluster -f $CLUSTER_NAME.yaml --install-nvidia-plugin=false --verbose 4 --kubeconfig "/root/.kube/config" 1> /root/create-eks.log 2>&1 &
# Install krew
curl -L https://github.com/kubernetes-sigs/krew/releases/download/v0.4.4/krew-linux_amd64.tar.gz -o /root/krew-linux_amd64.tar.gz
tar zxvf krew-linux_amd64.tar.gz
./krew-linux_amd64 install krew
export PATH="$PATH:/root/.krew/bin"
echo 'export PATH="$PATH:/root/.krew/bin"' >> /etc/profile
# Install krew plugin
kubectl krew install ctx ns get-all neat df-pv stern oomd view-secret # ktop tree
# Install Docker & Docker-compose
amazon-linux-extras install docker -y
systemctl start docker && systemctl enable docker
curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
# Install Kubecolor
wget https://github.com/kubecolor/kubecolor/releases/download/v0.5.0/kubecolor_0.5.0_linux_amd64.tar.gz
tar -zxvf kubecolor_0.5.0_linux_amd64.tar.gz
mv kubecolor /usr/local/bin/
# Install Kind
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.27.0/kind-linux-amd64
chmod +x ./kind
mv ./kind /usr/local/bin/kind
echo 'Userdata End!'
Outputs:
eksctlhost:
Value: !GetAtt OPSEC2.PublicIpUserData: 항목을 보면 eksctl, awscli v2, kube-ps1, krew, kubecolor 등 기타 플러그인을 설치 및 실습을 위한 환경변수 등을 설정하는 것을 볼 수 있습니다.
또한 cat << EOF > $CLUSTER_NAME.yaml 명령어를 통해 eksctl yaml 파일을 생성하고 eksctl create 명령어까지 수행합니다. 다음은 이번 실습에서 구성할 eks 클러스터 리소스 명세입니다.
cat << EOF > myeks.yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: myeks
region: ap-northeast-2
version: "1.31"
iam:
withOIDC: true # enables the IAM OIDC provider as well as IRSA for the Amazon CNI plugin
serviceAccounts: # service accounts to create in the cluster. See IAM Service Accounts
- metadata:
name: aws-load-balancer-controller
namespace: kube-system
wellKnownPolicies:
awsLoadBalancerController: true
vpc:
cidr: 192.168.0.0/16
clusterEndpoints:
privateAccess: true # if you only want to allow private access to the cluster
publicAccess: true # if you want to allow public access to the cluster
id: $VPCID
subnets:
public:
ap-northeast-2a:
az: ap-northeast-2a
cidr: 192.168.1.0/24
id: $PubSubnet1
ap-northeast-2b:
az: ap-northeast-2b
cidr: 192.168.2.0/24
id: $PubSubnet2
ap-northeast-2c:
az: ap-northeast-2c
cidr: 192.168.3.0/24
id: $PubSubnet3
addons:
- name: vpc-cni # no version is specified so it deploys the default version
version: latest # auto discovers the latest available
attachPolicyARNs: # attach IAM policies to the add-on's service account
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
configurationValues: |-
enableNetworkPolicy: "true"
- name: kube-proxy
version: latest
- name: coredns
version: latest
- name: metrics-server
version: latest
- name: aws-ebs-csi-driver
version: latest
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- amiFamily: AmazonLinux2023
desiredCapacity: 3
iam:
withAddonPolicies:
certManager: true # Enable cert-manager
externalDNS: true # Enable ExternalDNS
instanceType: t3.xlarge
preBootstrapCommands:
# install additional packages
- "dnf install nvme-cli links tree tcpdump sysstat ipvsadm ipset bind-utils htop -y"
labels:
alpha.eksctl.io/cluster-name: myeks
alpha.eksctl.io/nodegroup-name: ng1
maxPodsPerNode: 60
maxSize: 3
minSize: 3
name: ng1
ssh:
allow: true
publicKeyName: $SSHKEYNAME
tags:
alpha.eksctl.io/nodegroup-name: ng1
alpha.eksctl.io/nodegroup-type: managed
volumeIOPS: 3000
volumeSize: 100
volumeThroughput: 125
volumeType: gp3
EOF- 워커노드 InstanceType: t3.xlarge (4vCPU, 16GiB)
- ExternalDNS 설정
모니터링과 관측 가능성에 대하여
위 실습환경을 구성하는 데에는 약 20분 정도 소요가 됩니다. 해당 포스팅을 실시간으로 따라하고 계신다면 리소스가 프로비저닝 되는 동안 가볍게 최근 화두가되는 Observability(관측가능성)에 대하여 간단히 알아보는 시간을 가져보겠습니다.

저희가 흔히 알고 있는 모니터링과 관측 가능성은 다음과 같은 차이가 있습니다.
모니터링
- 시스템 성능과 상태를 감시하여 사전에 정의된 기준을 초과하면 경고를 발송하는 방식
- CPU, 메모리, 응답 시간 등 특정 메트릭을 지속적으로 측정
- 주로 단순한 시스템에서 사용되며, 예상된 문제를 감지하는 역할
관측 가능성
- 로그, 메트릭, 트레이스를 기반으로 예상치 못한 문제까지 분석하는 능력
- 클라우드 및 분산 시스템에서 내부 상태를 이해하는 데 필수적
- 미리 정의된 기준 없이 동적 분석이 가능하며, 시스템 최적화에 활용
차이점
- 목적: 모니터링은 문제 감지, 관측 가능성은 원인 분석
- 데이터: 모니터링은 미리 정의된 메트릭, 관측 가능성은 로그·트레이스 포함
- 적용 환경: 모니터링은 단순한 시스템, 관측 가능성은 마이크로서비스 등에 적합
- 사용 방식: 모니터링은 경고 기반, 관측 가능성은 동적 쿼리와 분석 가능

관측 가능성은 단순 감시를 넘어 복잡한 시스템 문제 해결과 최적화에 중요한 역할을 합니다.
최근에 Observability가 주목받는 이유는 그만큼 수요가 증가하고 있기 때문일 텐데요. 그 이유는 저희가 지금 까지 공부하고 있는 기술인 쿠버네티스 혹은 컨테이너, 즉 Micro Service Architecture 와 같은 앱 현대화로 인해 trace가 복잡해지고 한 개의 트랜잭션이 여러개의 세분화된 처리로 chunking 되면서 관계복잡성이 증가했기 때문입니다.
관측 가능성의 3대 주요 요소

- Metrics (메트릭)
- 수치화된 데이터(시간 단위의 성능 지표)
- 예: CPU 사용률, 메모리 사용량, 요청 응답 시간
- 시스템의 전반적인 상태를 파악하는 데 유용
- 사용 예: AWS CloudWatch, Prometheus
- Traces (트레이스)
- 분산 시스템에서 요청(Request)의 흐름을 추적
- 예: 마이크로서비스 환경에서 한 요청이 여러 서비스(서버, DB, API 등)를 거치는 과정 기록
- 문제 발생 시, 어디에서 병목 현상이 발생하는지 분석하는 데 도움
- 사용 예: AWS X-Ray, Jaeger, OpenTelemetry
- Logs (로그)
- 시스템 이벤트 및 오류 기록 (텍스트 기반)
- 예: 애플리케이션 에러 메시지, 사용자 활동 기록, API 요청 내역
- 문제 발생 시, 세부 원인 분석에 사용됨
- 사용 예: AWS CloudWatch Logs, ELK Stack (Elasticsearch, Logstash, Kibana)
이러한 Metrics, Traces, Logs를 수집하고 전송하는데 사용되는 기술을 High-level 한 용어로 Telemetry 라고도 합니다. 텔레메트리에 대해 조금 더 자세한 내용은 제가 이전에 작성한 포스팅을 참고 바랍니다. 🔗
설치 확인 (운영서버)
# 운영서버 EC2 IP 확인
aws cloudformation describe-stacks --stack-name **myeks** --query 'Stacks[*].**Outputs[0]**.OutputValue' --output textssh -i **<SSH 키 파일 위치>** **ec2-user**@$(aws cloudformation describe-stacks --stack-name **myeks** --query 'Stacks[*].Outputs[0].OutputValue' --output text)
ssh -i **~/.ssh/josh-key-1.pem** **ec2-user**@$(aws cloudformation describe-stacks --stack-name **myeks** --query 'Stacks[*].Outputs[0].OutputValue' --output text)
-------------------------------------------------
#
whoami
pwd
# cloud-init 실행 과정 로그 확인
tail -f /var/log/cloud-init-output.log
# eks 설정 파일 확인
cat myeks.yaml
# cloud-init 정상 완료 후 **eksctl 실행 과정 로그** 확인
tail -f /root/create-eks.log
#
exit
-------------------------------------------------위 myeks-4week.yaml 파일에서 eksctl creat --verbose 옵션을 사용하여 create-eks.log 에 설치 기록을 남겨두었습니다. 해당 파일에서 클러스터 구성 로그를 조회할 수 있습니다. 운영서버 ec2 에 접근하여 해당 로그파일을 확인합니다.

실습에 사용될 환경변수도 확인해 줍니다.
**export | egrep 'ACCOUNT|AWS_|CLUSTER|KUBERNETES|VPC|Subnet' | egrep -v 'KEY'**
운영서버에서 워커노드 및 클러스터 관리를 위한 기본 설정 작업을 해줍니다.
# 인스턴스 정보 확인
aws ec2 describe-instances --query "Reservations[*].Instances[*].{InstanceID:InstanceId, PublicIPAdd:PublicIpAddress, PrivateIPAdd:PrivateIpAddress, InstanceName:Tags[?Key=='Name']|[0].Value, Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
# 노드 IP 확인 및 PrivateIP 변수 지정
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
N3=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3
# 노드 IP 로 ping 테스트
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ping -c 1 $i ; echo; done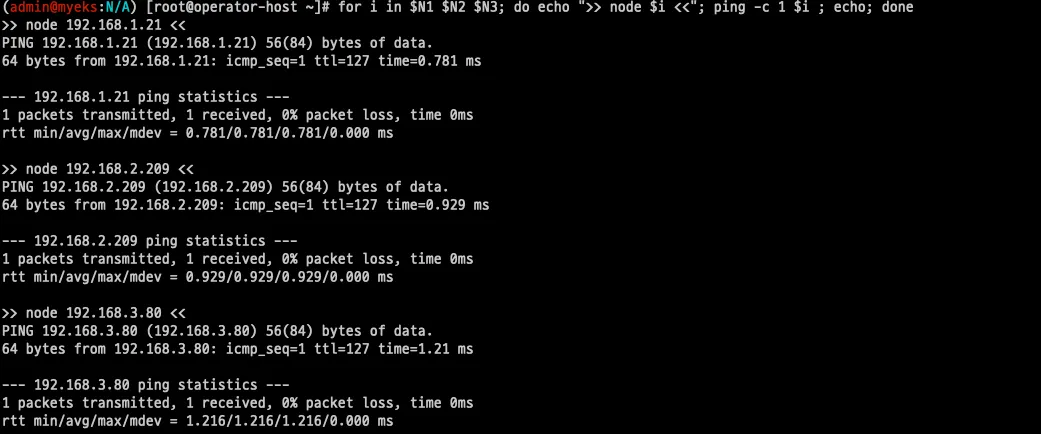
노드 IP 정보 확인
실습에 사용될 노드 정보와 환경변수 설정을 해줍니다.
# 인스턴스 정보 확인
aws ec2 describe-instances --query "Reservations[*].Instances[*].{InstanceID:InstanceId, PublicIPAdd:PublicIpAddress, PrivateIPAdd:PrivateIpAddress, InstanceName:Tags[?Key=='Name']|[0].Value, Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
# EC2 공인 IP 변수 지정
export N1=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=myeks-ng1-Node" "Name=availability-zone,Values=ap-northeast-2a" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N2=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=myeks-ng1-Node" "Name=availability-zone,Values=ap-northeast-2b" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N3=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=myeks-ng1-Node" "Name=availability-zone,Values=ap-northeast-2c" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
echo $N1, $N2, $N3
# *remoteAccess* 포함된 보안그룹 ID
aws ec2 describe-security-groups --filters "Name=group-name,Values=*remoteAccess*" | jq
export MNSGID=$(aws ec2 describe-security-groups --filters "Name=group-name,Values=*remoteAccess*" --query 'SecurityGroups[*].GroupId' --output text)
# 해당 보안그룹 inbound 에 자신의 집 공인 IP 룰 추가
aws ec2 authorize-security-group-ingress --group-id $MNSGID --protocol '-1' --cidr $(curl -s ipinfo.io/ip)/32
# 해당 보안그룹 inbound 에 운영서버 내부 IP 룰 추가
aws ec2 authorize-security-group-ingress --group-id $MNSGID --protocol '-1' --cidr 172.20.1.100/32
# 워커 노드 SSH 접속
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh -o StrictHostKeyChecking=no ec2-user@$i hostname; echo; done
ssh ec2-user@$N1
exit
ssh ec2-user@$N2
exit
ssh ec2-user@$N2
exit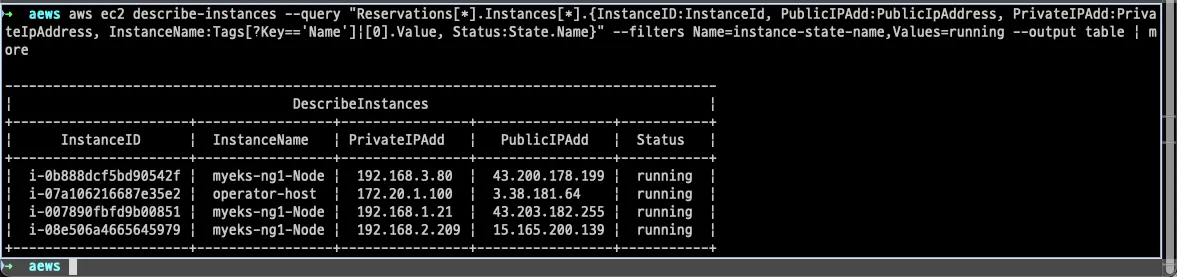
설치확인(로컬환경)
또한 본인의 로컬환경에서 kubeconfig를 업데이트 하여 신규 생성된 클러스터 인증정보를 갱신합니다.
# kubeconfig 생성
aws sts get-caller-identity --query Arn
aws eks **update-kubeconfig** --name myeks --user-alias <위 출력된 자격증명 사용자>
*aws eks update-kubeconfig --name myeks --user-alias admin*
****#
kubectl cluster-info
**kubectl ns default**
kubectl get node -v6
**kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone**
**kubectl get pod -A**
kubectl get pdb -n kube-system
# krew 플러그인 확인
kubectl krew list
kubectl get-allEKS 배포 후 실습 편의를 위한 환경변수 설정
# 변수 지정
export CLUSTER_NAME=myeks
export VPCID=$(aws ec2 describe-vpcs --filters "Name=tag:Name,Values=$CLUSTER_NAME-VPC" --query 'Vpcs[*].VpcId' --output text)
export PubSubnet1=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet1" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet2=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet2" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet3=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet3" --query "Subnets[0].[SubnetId]" --output text)
export N1=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node" "Name=availability-zone,Values=ap-northeast-2a" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N2=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node" "Name=availability-zone,Values=ap-northeast-2b" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N3=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node" "Name=availability-zone,Values=ap-northeast-2c" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text) #사용 리전의 인증서 ARN 확인
MyDomain=gasida.link # 각자 자신의 도메인 이름 입력
MyDnzHostedZoneId=$(aws route53 list-hosted-zones-by-name --dns-name "$MyDomain." --query "HostedZones[0].Id" --output text)
# [신규 터미널] 확인
echo $CLUSTER_NAME $VPCID $PubSubnet1 $PubSubnet2 $PubSubnet3
echo $N1 $N2 $N3 $MyDomain $MyDnzHostedZoneId
tail -n 15 ~/.zshrc
kube-ops-view(Ingress), AWS LoadBalancer Controller, ExternalDNS, gp3 storageclass 설치
실습에 사용될 리소스를 설치하여 줍니다.
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=ClusterIP --set env.TZ="Asia/Seoul" --namespace kube-system
# gp3 스토리지 클래스 생성
cat <<EOF | kubectl apply -f -
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp3
annotations:
storageclass.kubernetes.io/is-default-class: "true"
allowVolumeExpansion: true
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
allowAutoIOPSPerGBIncrease: 'true'
encrypted: 'true'
fsType: xfs # 기본값이 ext4
EOF
kubectl get sc
# ExternalDNS
curl -s https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml | MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst | kubectl apply -f -
# AWS LoadBalancerController
helm repo add eks https://aws.github.io/eks-charts
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
# kubeopsview 용 Ingress 설정 : group 설정으로 1대의 ALB를 여러개의 ingress 에서 공용 사용
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
labels:
app.kubernetes.io/name: kubeopsview
name: kubeopsview
namespace: kube-system
spec:
ingressClassName: alb
rules:
- host: kubeopsview.$MyDomain
http:
paths:
- backend:
service:
name: kube-ops-view
port:
number: 8080
path: /
pathType: Prefix
EOF

설치 확인
# 설치된 파드 정보 확인
kubectl get pods -n kube-system
# service, ep, ingress 확인
kubectl get ingress,svc,ep -n kube-system
# Kube Ops View 접속 정보 확인
echo -e "Kube Ops View URL = https://kubeopsview.$MyDomain/#scale=1.5"
open "https://kubeopsview.$MyDomain/#scale=1.5" # macOS

Bookinfo 설치 (샘플 애플리케이션)

실습으로 사용할 샘플 애플리케이션을 설치해줍니다. 실질적인 모니터링과 트래픽 확인을 위해서 트래픽이 필요하므로 트래픽 부하를 조절할 수 있는 샘플 애프리케이션 입니다. 자세한 내용은 다음 링크를 참고 바랍니다.
- https://istio.io/latest/docs/examples/bookinfo/
- https://github.com/istio/istio/blob/master/samples/bookinfo/platform/kube/bookinfo.yaml
kubectl apply -f https://raw.githubusercontent.com/istio/istio/refs/heads/master/samples/bookinfo/platform/kube/bookinfo.yaml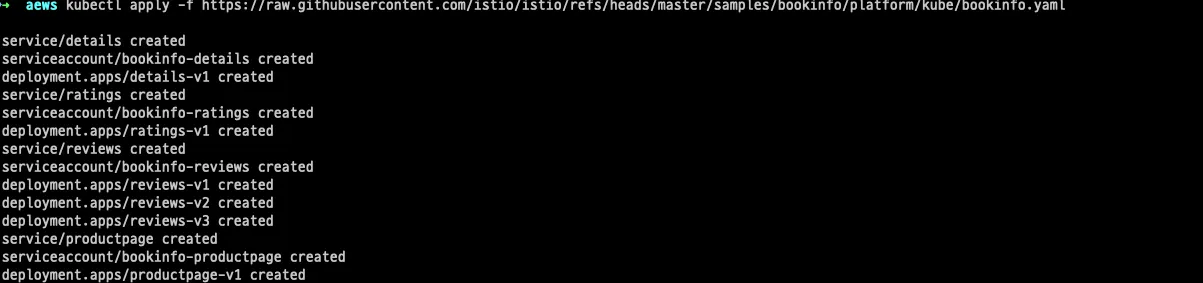
설치 확인
# 확인
kubectl get all,sa
# product 웹 접속 확인
kubectl exec "$(kubectl get pod -l app=ratings -o jsonpath='{.items[0].metadata.name}')" -c ratings -- curl -sS productpage:9080/productpage | grep -o "<title>.*</title>"
# 로그
kubectl stern -l app=productpage
혹은
kubectl logs -l app=productpage -f

EKS 모니터링
AWS EKS 클러스터 모니터링 (AWS Native)
사실 자체적인 클러스터(self-manged kubernets)를 구성하면 모니터링을 하기 위해 여러가지 오픈소스 및 커스텀 환경에 많은 신경을 써야 할 필요가 있습니다. 하지만 AWS EKS 서비스를 사용하면 AWS 의 기존 다양한 서비스와의 연동을 통해 모니터링 환경을 쉽게 구축할 수 있습니다. 다음은 AWS 에서 자체적으로 제공하는 서비스 입니다.
| 영역 | 도구 | 설명 | 설정 |
|---|---|---|---|
| 컨트롤 플레인 | 관찰성 대시보드 | 지원되는 버전의 경우 관찰성 대시보드를 통해 클러스터의 성능을 확인할 수 있습니다. 이를 통해 문제를 신속하게 감지 및 해결할 수 있습니다. | 설정 절차 |
| 애플리케이션/컨트롤 플레인 | Prometheus | Prometheus를 사용하여 애플리케이션과 컨트롤 플레인에 대한 지표와 경고를 모니터링할 수 있습니다. | 설정 절차 |
| 애플리케이션 | CloudWatch Container Insights | CloudWatch Container Insights는 컨테이너 애플리케이션 및 마이크로서비스의 지표 및 로그를 수집하고 종합하며 요약합니다. | 설정 절차 |
| 애플리케이션 | AWS Distro for OpenTelemetry(ADOT) | ADOT는 상호 연관된 지표, 추적 데이터, 메타데이터를 수집해서 AWS 모니터링 서비스 또는 파트너로 전송합니다. CloudWatch Container Insights를 통해 설정할 수 있습니다. | 설정 절차 |
| 애플리케이션 | Amazon DevOps Guru | Amazon DevOps Guru는 노드 수준의 운영 성능 및 가용성을 감지합니다. | 설정 절차 |
| 애플리케이션 | AWS X-Ray | AWS X-Ray는 애플리케이션에 대한 추적 데이터를 수신합니다. 이 추적 데이터에는 수신 및 발신 요청과 요청에 대한 메타데이터가 포함됩니다. Amazon EKS의 경우 구현하려면 OpenTelemetry 추가 기능이 필요합니다. | 설정 절차 |
| 애플리케이션 | Amazon CloudWatch | CloudWatch는 지원되는 버전에서 몇 가지 기본 Amazon EKS 지표를 무료로 제공합니다. CloudWatch Observability Operator를 사용하여 이 기능을 확장하고 지표, 로그 및 추적 데이터의 수집을 처리할 수 있습니다. | 설정 절차 |
EKS 컨트롤 플레인 로깅
컨트롤 플레인의 다양한 컴포넌트에 대해서 로그를 활성화/비활성화 할 수 있습니다. AWS EKS 클러스터를 생성할 때 컨트롤 플레인 로그는 기본적으로 비활성화되어 있습니다.
이는 AWS 콘솔에서도 설정할 수 있고 cli를 통해 설정할 수도 있습니다.

로깅 활성화 하기

AWS 콘솔에서 활성화
aws eks **update-cluster-config** --region **ap-northeast-2** --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["**api**","**audit**","**authenticator**","**controllerManager**","**scheduler**"],"enabled":**true**}]}'로깅 확인
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
**aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver-audit --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-scheduler --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix authenticator --follow**
**aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix cloud-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1**
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short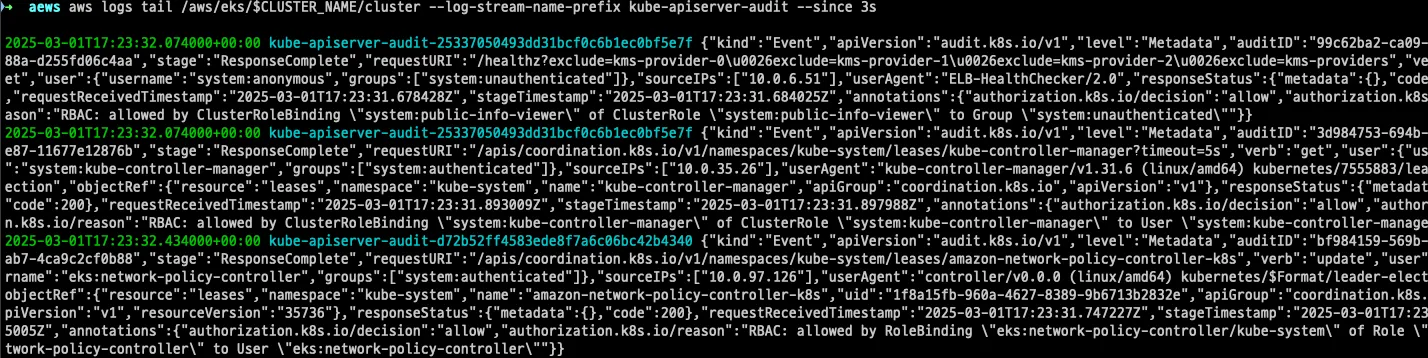
aws logs 명령어를 사용하면 컨트롤플레인 로그를 확인할 수 있습니다. 이 때 api-server, kube-controller 등의 컴포넌트는 각각 다른 로그 스트림으로 분리되므로 명령어에 로그스트림을 지정하여 개별적으로도 확인할 수 있습니다.

하지만 이러한 raw 데이터의 로그는 육안으로는 도저히 확인하기 쉽지 않을 것입니다. 따라서 여러 툴과 프로그램을 사용하여 분석해야 하지만 AWS에서는 이러한 로그들이 CloudWatch LogGroup에서 관리되므로 별도의 구성 없이 CloudWatch의 Log Insights 등을 통해 간단한 쿼리를 사용하여 조회할 수 있습니다.
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /**NodeNotReady**/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "**kube-apiserver-audit**"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "**kube-scheduler**"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "**authenticator**"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "**kube-controller-manager**"
| sort @timestamp desc 
EKS 파드 모니터링
컨트롤 플레인의 모니터링도 중요하지만 워크로드를 실행하는 실질적인 파드의 모니터링 또한 아주 중요합니다. 이때 관측가능성의 영역은 더 중요해집니다.
파드의 모니터링을 확인하기 위해 nginx 기반의 웹서버를 생성하도록 합니다.
helm repo 업데이트
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
nginx 호스팅을 위한 인그레스와 워크로드 리소스를 생성하여줍니다.
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
resourcesPreset: "nano"
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
EOT
# 배포
helm install nginx bitnami/nginx --version 19.0.0 -f nginx-values.yaml
설치 확인
# 확인
kubectl get ingress,deploy,svc,ep nginx
kubectl describe deploy nginx # Resource - Limits/Requests 확인
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl stern deploy/nginx
혹은
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s https://nginx.$MyDomain | grep title; date; sleep 1; done
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
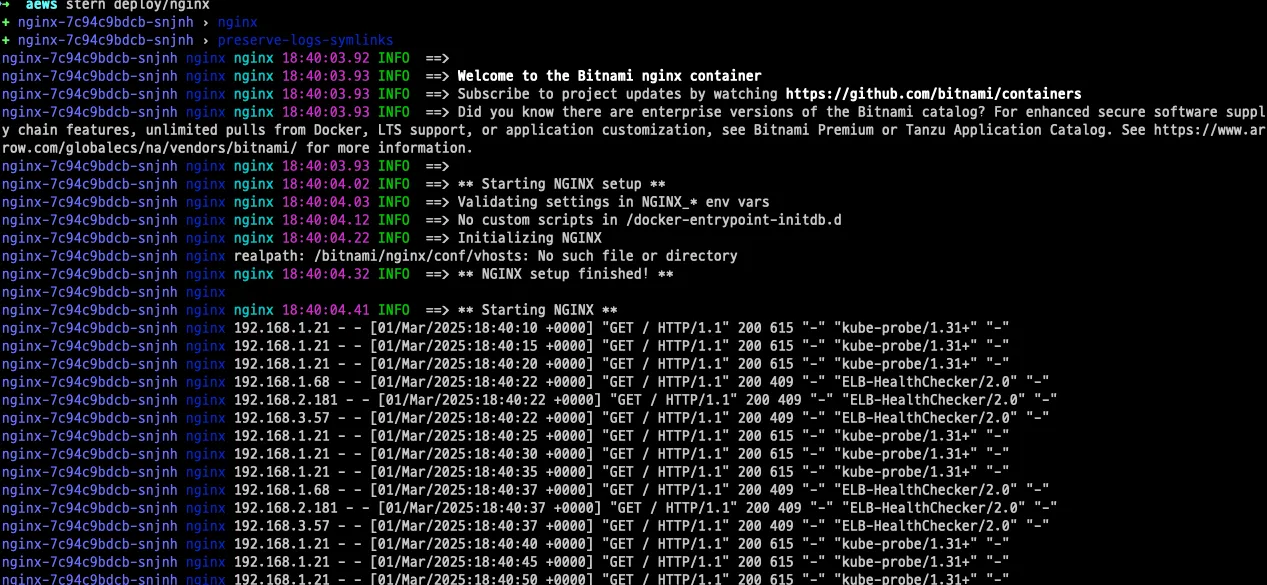
※ 기본적으로 컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고합니다. 🔗
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이, 애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능합니다. 혹은 stern을 사용하여 좀더 가시성 있게 확인합니다.
- kubectl logs로 모니터링
# 로그 모니터링 kubectl stern deploy/nginx 혹은 kubectl logs deploy/nginx -f # nginx 웹 접속 시도 # 컨테이너 로그 파일 위치 확인 kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/

⚠️ 하지만 이렇듯 stderr, stdout 으로 생성된 로그는 해당 파드가 종료(evict)되면 확인할 수 없습니다. 이는 관측가능성이 떨어지는 부분이라고 볼 수 있습니다. 따라서 중요 로그 같은 경우에는 반드시 외부 로그 저장소로 보관할 수 있는 구성을 만들어주어야 합니다.
※ kubelet 기본 설정은 로그 파일의 최대 크기가 10Mi로 10Mi를 초과하는 로그는 전체 로그 조회가 불가능합니다. 이는 kubelet 구성 파일 경로에서 살펴볼 수 있습니다: --config-dir=/etc/kubernetes/kubelet.conf.d - Docs , Ref
이렇듯 AWS EKS 자체 로깅 기능과 kubectl logs 같은 방법으로 쿠버네티스 로그를 직접 조회하는 방법을 살펴봤습니다. 하지만 이렇게 raw 한 형태로 로그 및 시스템 지표를 살펴보는 것은 가시성이 떨어지고 정보 분석에 한계가 있습니다. 따라서 이를 시각화 하고 쿼리언어로 분석하기 위해 저희는 다양한 방법을 사용합니다.
프로메테우스 설치하기
프로메테우스란?
들어가며: 프로메테우스 소개 영상을 한번 시청해 보시기를 추천드립니다.

Prometheus는 CNCF(Cloud Native Computing Foundation)가 후원하는 오픈소스 모니터링 및 알림 시스템입니다. 시계열(Time-series) 데이터 수집 및 분석을 주 목적으로 하며, Kubernetes와 같은 클라우드 네이티브 환경에서 성능 모니터링 및 메트릭 수집을 위해 널리 사용됩니다.
로고를 보면 프로메테우스의 불을 상징하는 그림이 그려져있는데, 인류는 이 불을 이용해서 엄청난 발전을 거듭했었죠. 이러한 혁신적 의미의 상징과 더불어 보이지 않는 것을 볼 수 있게 된 것, 즉 관측가능성에 관련한 의미도 있다고 생각합니다.최초의 ‘불’을 발견하고 나서 인류는 밤을 정복하게 됩니다. 아무것도 보이지 않는 어둠속에서 무언가를 볼수 있게 된 것입니다.
프로메테우스 특징
프로메테우스는 다음과 같은 기능과 특징을 가지고 있습니다. 이러한 강력한 기능을 기반으로 아직까지도 오픈소스 모니터링 도구 중에는 가장 많은 선택을 받는 것 같습니다. 오픈소스 중에서는 de facto라고도 할수 있겠습니다.
- 시계열 데이터 수집
- 애플리케이션, 컨테이너, 네트워크 등의 메트릭(metric)을 실시간으로 수집
- 데이터는 시계열(Time-series) DB에 저장됨
- 다양한 데이터 소스 지원 (Pull 방식)
- _HTTP 엔드포인트(Pull 방식)*_를 통해 메트릭을 수집
- Kubernetes, Node Exporter, cAdvisor 등 다양한 Exporter를 통해 데이터 수집 가능
- 강력한 쿼리 언어 (PromQL)
- Prometheus는 자체적인 PromQL(Prometheus Query Language)을 제공하여 데이터를 분석하고 시각화 가능
- Alertmanager와 연동 가능
- 경고(Alert) 시스템을 통해 특정 임계값을 초과하면 Slack, PagerDuty, 이메일로 알림 전송
- Kubernetes와 완벽한 통합
- Kubernetes 클러스터의 Pod, 노드, 서비스 등의 메트릭을 자동으로 수집
kube-state-metrics,cAdvisor등과 함께 사용됨
프로메테우스 스택 설치
다음은 프로메테우스의 구성도 입니다. 프로메테우스는 기본적으로 메트릭 을 Pull 하는 폴링데이터 방식의 수집을 사용합니다. 프로메테우스 서버는 이런한 데이터를 수집하여 중앙에서 관리하고 Agent기능을 하는 Exporter 가 노드에서 실제 데이터를 수집합니다. Exporter는 수많은 종류가 있고 그 중에서 NodeExporter 가 가장 많이 사용되며 기본 시스템 지표를 수집하는 Exporter 입니다.
프로메테우스의 개념을 한번에 설명드리긴 어려우니 다음 포스팅을 참고 하시면 좋을 것 같습니다. 🔗

프로메테우스는 K8S Native 한 환경에서 뿐만 아니라 일반적인 서버에서도 직접 설치가 가능합니다. (Prometheus, node-exporter 설치 및 구성)
하지만 K8S 환경에서 설치한다면 helm 차트를 통해 쉽고 빠르게 구성할 수 있습니다. kube-prometheus-stack
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
alertmanager:
enabled: false
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
cat monitor-values.yaml- kube-prometheus-stack 차트에서 쓰일 파라미터를 설정
- 프로메테우스와 그라파나에 대한 인그레스 각각 구성
- PV 사용. 메트릭 보관을 위해 영구 스토리지 사용
- retention 사용하여 라이프싸이클 적용
- 얼럿매니저 비활성화
- ❓kubeControllerManager, kubeScheduler, kubeEtcd 비활성화
- 컨트롤플레인 컴포넌트로 AWS 관리영역 이므로 수집이 안되므로 비활성화 함
- 이를 인위적으로 활성화 하는 방법은 다음 문서를 참고 바랍니다. 🔗
배포 및 확인
위 아키텍처의 각각의 컴포넌트들이 생성된 것을 확인할 수 있습니다.
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana-0 : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get sts,ds,deploy,pod,svc,ep,ingress,pvc,pv -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring
kubectl df-pv
# 프로메테우스 버전 확인
echo -e "https://prometheus.$MyDomain/api/v1/status/buildinfo"
open https://prometheus.$MyDomain/api/v1/status/buildinfo # macOS
kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version
prometheus, version 3.1.0 (branch: HEAD, revision: 7086161a93b262aa0949dbf2aba15a5a7b13e0a3)
...
# 프로메테우스 웹 접속
echo -e "https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" # macOS
# 그라파나 웹 접속
echo -e "https://grafana.$MyDomain"
open "https://grafana.$MyDomain" # macOS

위 템플릿에서 지정한 패스워드를 입력해줍니다. user는 기본 적으로 admin이 생성됩니다.

Explore 메뉴에서 간단하게 메트릭을 조회해보면 수집이 잘 되고 있는 것을 확인할 수 있습니다. 이 때 PromQL을 직접 작성하지 않더라도 간단하게 GUI를 사용해 PromQL을 작성할 수 있습니다.
AWS 에서 리소스 확인
AWS ALB를 살펴보면 Ingress-alb에 호스트 기반 규칙으로 그라파나와 프로메테우스 서비스가 라우팅 되는 것을 확인할 수 있습니다.


프로메테우스 사용(활용)하기
AWS CNI Metrics 수집 (PodMonitor)
서비스 운영을 하다보면 네트워크 장애가 종종 발생하게 됩니다. 이때 보다 심층적인 모니터링을 위해서 AWS CNI 의 지표를 수집할 수 있도록 설정하여줍니다.
❓PodMonitor란
- PodMonitor는 Pod의 메트릭을 직접 수집하는 Prometheus Operator의 CRD(Custom Resource Definition)
- Service 없이 Pod의 메트릭을 감시할 때 사용 (ServiceMonitor는 Service를 통해 메트릭을 수집)
- Kubernetes 환경에서 서비스 없이 메트릭을 노출하는 Pod를 모니터링할 때 유용
PodMonitor 설치
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: **PodMonitor**
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
**jobLabel**: k8s-app
namespaceSelector:
matchNames:
- kube-system
**podMetricsEndpoints**:
- interval: 30s
path: **/metrics**
port: **metrics**
selector:
matchLabels:
**k8s-app: aws-node**
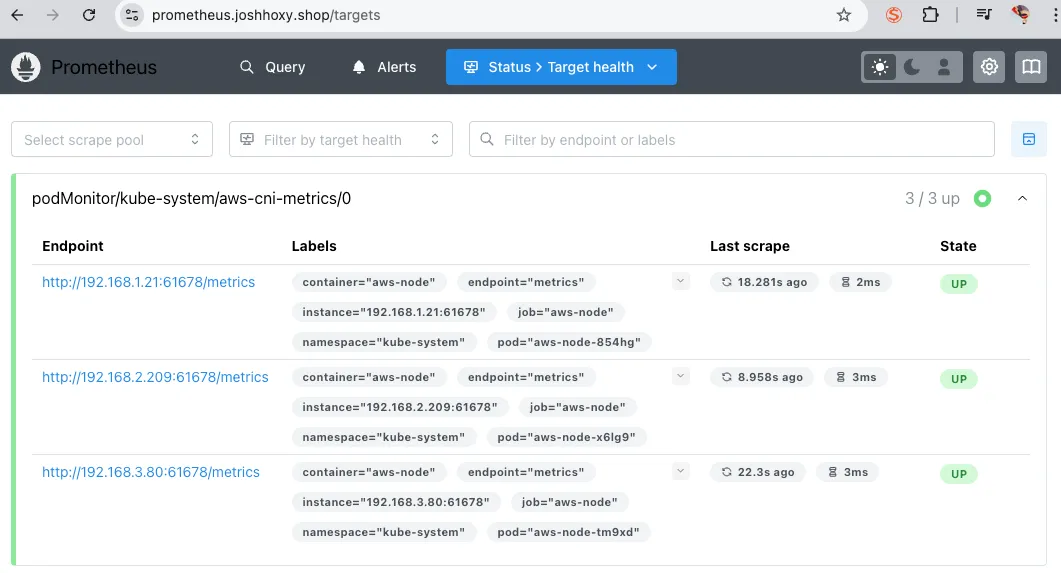
EOF설치 확인
# PodMonitor 확인
kubectl get podmonitor -n kube-system
**kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml** | kubectl neat
****# metrics url 접속 확인
**curl -s $N1:61678/metrics | grep '^awscni'**
status> Target Health 를 확인하면 대상 파드를 확인할 수 있습니다. 61678 포트는 AWS k8s Agent가 사용하는 포트로 AWS CNI도 잘 떠있다는 것을 알 수있습니다.
프로메테우스 기능 살펴보기
open "https://prometheus.$MyDomain" 명령어를 사용하여 들어가보면 다음과 같은 화면이 메인화면으로 나타납니다.

1. 쿼리(Query) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회


그 중 하나를 골라서 (+) 버튼을 눌러줍니다.

그러면 다음과 같이 커맨드 창에 해당 지표가 작성됩니다. 그후 Excute 버튼을 눌러 실행해줍니다.

다음과 같이 result가 조회 됩니다.

이 때, Graph 버튼을 누르면 시각적인 데이터로 보여줍니다.

2. 경고(Alerts) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
Alerts는 이번 실습에서 AlertsManager 기능을 비활성화 했기 때문에 따로 확인할 수는 없습니다. 보통 쿠버네티스 모니터링 환경을 구성할 때는 프로메테우스에서 Alert을 설정하기 보다는 Grafana 혹은 다른 APM 등에서 설정하기 때문에 잘 쓰지않는 기능입니다.


3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인
타겟 헬스를 살펴보면 대상으로 설정한 각각의 노드 혹은 파드가 잘 떠있는지 확인 가능합니다.

그 외 TSDB status, Service Discovery 등의 상태를 확인할 수 있으므로 프로메테우스 운영의 전반적인 상태를 체크할 수 있습니다.
프로메테우스 설정 (웹서버)
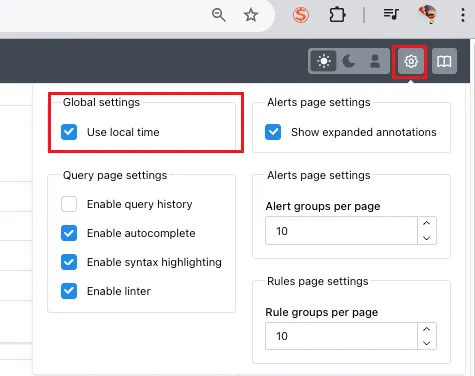
- Use local time : 출력 시간을 로컬 타임으로 변경. 로컬 타임으로 보는 것이 아무래도 편하니 켜줍니다.
나머지 기능은 default 옵션으로 사용해도 좋습니다.
- Enable query history : PromQL 쿼리 히스토리 활성화
- Enable autocomplete : 자동 완성 기능 활성화
- Enable highlighting : 하이라이팅 기능 활성화
- Enable linter : 문법 오류 감지, 자동 코스 스타일 체크
프로메테우스 설정 (config)

기본 config는 다음과 같습니다. 전문은 너무 길어서 일부 내용만 발췌하였습니다.
**global**:
scrape_interval: 15s # 메트릭 가져오는(scrape) 주기
scrape_timeout: 10s # 메트릭 가져오는(scrape) 타임아웃
evaluation_interval: 15s # alert 보낼지 말지 판단하는 주기
...
- **job_name**: **serviceMonitor**/monitoring/**kube-prometheus-stack-prometheus-node-exporter**/0
scrape_interval: 30s
scrape_timeout: 10s
**metrics_path**: /metrics
**scheme**: http
...
**relabel_configs**:
- source_labels: [job]
separator: ;
target_label: **__tmp_prometheus_job_name**
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_instance, __meta_kubernetes_service_labelpresent_app_kubernetes_io_instance]
separator: ;
regex: (**kube-prometheus-stack**);true
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name, __meta_kubernetes_service_labelpresent_app_kubernetes_io_name]
separator: ;
regex: (**prometheus-node-exporter**);true
replacement: $1
action: keep
...
**kubernetes_sd_configs**: # 서비스 디스커버리(SD) 방식을 이용하고, 파드의 엔드포인트 List 자동 반영
- role: **endpoints** # 서비스에 연결된 엔드포인트(Pod IP + Port) 탐색
kubeconfig_file: "" # Prometheus가 실행 중인 환경의 기본 kubeconfig 사용
follow_redirects: true # 엔드포인트를 변경할 경우 이를 따라감
enable_http2: true
namespaces:
own_namespace: false # 자신이 실행 중인 네임스페이스가 아닌 곳에서도 탐색 가능
names:
- monitoring # 서비스 엔드포인트가 속한 네임 스페이스 이름을 지정 : monitoring 네임스페이스에 있는 서비스만 타겟팅, 서비스 네임스페이스가 속한 포트 번호를 구분하여 메트릭 정보를 가져옴
...
- **job_name**: **podMonitor**/kube-system/**aws-cni-metrics**/0
honor_timestamps: true
...
**relabel_configs**:
- source_labels: [job]
separator: ;
target_label: **__tmp_prometheus_job_name**
replacement: $1
action: replace # job 라벨 값을 __tmp_prometheus_job_name에 저장
- source_labels: [__meta_kubernetes_pod_label_k8s_app, __meta_kubernetes_pod_labelpresent_k8s_app]
separator: ;
regex: (**aws-node**);true
replacement: $1
action: keep # Pod의 k8s_app 라벨 값이 aws-node인 경우만 유지
...
**kubernetes_sd_configs**:
- role: **pod** # 클러스터 내 모든 개별 Pod 탐색
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- **kube-system**
...해당 config는 서비스 디스커버리 설정과 파드모니터 설정에 대한 내용으로 어떤 대상을 수집할 지에 대해서 정의하는 설정과 관련된 내용입니다.
- kubernetes_sd_configs.role: pod → Pod 기반 서비스 디스커버리 활성화
- relabel_configs → 특정 Pod만 필터링 (prometheus.io/scrape: true인 Pod만 수집)
- source label 이 [job, __meta_kubernetes_service_label_app_kubernetes_io_instance, __meta_kubernetes_service_labelpresent_app_kubernetes_io_instance, __meta_kubernetes_service_labelpresent_app_kubernetes_io_name …] 등 인것들에 대해서 수집하도록 설정

그외 config 에서 살펴볼만한 설정은 다음과 같습니다.
- scrape_interval: 15s: 15초마다 메트릭 수집 (기본 1m보다 짧음)
- scrape_timeout: 10s: 10초 내 응답 없으면 타임아웃
- evaluation_interval: 15s: 15초마다 Alerting Rule 평가
- relabel_configs: 특정 라벨을 기반으로 타겟 필터링
- metric_relabel_configs: 특정 메트릭을 필터링하여 스토리지 절약
- tls_config: API 서버 및 Kubelet 인증 설정 포함
- storage.tsdb.outofordertimewindow: 0: Out-of-Order 데이터 허용 안 함
서비스 디스커버리
- 동적으로 모니터링 대상(Targets)을 탐색하는 기능
- 수동으로
targets를 설정하는 대신, 클러스터 내부의 서비스, 노드, 엔드포인트를 자동으로 발견 - Kubernetes, EC2, Consul, DNS, File 기반 등 다양한 방식 지원

다양한 엔드포인트가 발견된 것을 확인할 수 있습니다.
Nginx 웹서버 프로비저닝

현재 클러스터에서 Nginx를 신규로 프로비저닝 하면 어떻게 동작할까요? 다음과 같은 서비스 모니터에 의해서 새로운 엔드포인트가 생성되어 메트릭을 수집하는 과정을 살펴보도록 하겠습니다.
서비스 모니터를 사용하여 파드가 살아있는 대상에 한해서만 로그를 수집합니다. 이는 데이터 수집 부하를 줄이고 효율적인 운영을 하기 위한 기능입니다. 이는 중앙 관리 컨트롤러인 Prometheus Operator과 Service Monitor의 동작으로 자동으로 운영됩니다.
동작과정은 다음과 같습니다.
Kubernetes Service가 Pod을 찾고 Endpoints를 설정
- Service 객체는 Label Selector를 이용해 관련 Pod을 검색
- 해당 Pod의 Endpoints 정보를 수집하여 저장 (Scrape Target 지정)
ServiceMonitor가 Service를 찾고 Endpoints를 탐색
- ServiceMonitor가 Label Selector를 사용해 관련 Service를 찾음
- Service에 연결된 Endpoints를 탐색하여 어떤 Pod에서 메트릭을 가져올지 확인
Prometheus Operator가 ServiceMonitor를 감지하고 Scrape 설정 생성
- Prometheus Operator가 ServiceMonitor를 감지하여 해당 Service를 매칭
- ServiceMonitor와 Endpoints 정보를 기반으로 Prometheus의 scrape configuration을 생성
config-reloader가 새로운 설정을 Prometheus에 반영하여 자동으로 모니터링 대상 추가

위 실습 과정에서 생성한 Nginx에 대한 메트릭 수집 설정을 하려면 exporter 컨테이너를 추가해 주어야 합니다. 해당 컨테이너는 사이드카 방식으로 Nginx 데이터를 수집합니다.
nginx 웹 서버(with helm)에 metrics 수집 설정 추가 - Helm
# 모니터링
watch -d "kubectl get pod; echo; kubectl get servicemonitors -n monitoring"
# nginx 파드내에 컨테이너 갯수 확인
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용
# The chart can deploy ServiceMonitor objects for integration with Prometheus Operator installations. To do so, set the value metrics.serviceMonitor.enabled=true.
cat <<EOT > nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx-values.yaml
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
kubectl get servicemonitor -n monitoring nginx -o yaml | kubectl neat
버전이 리비전 되어 2 버전으로 업데이트된 것을 확인할 수 있습니다.
또한 파드를 조회해 보면 nginx 컨테이너 외에 metric 컨테이너가 추가된 것을 확인할 수 있습니다.
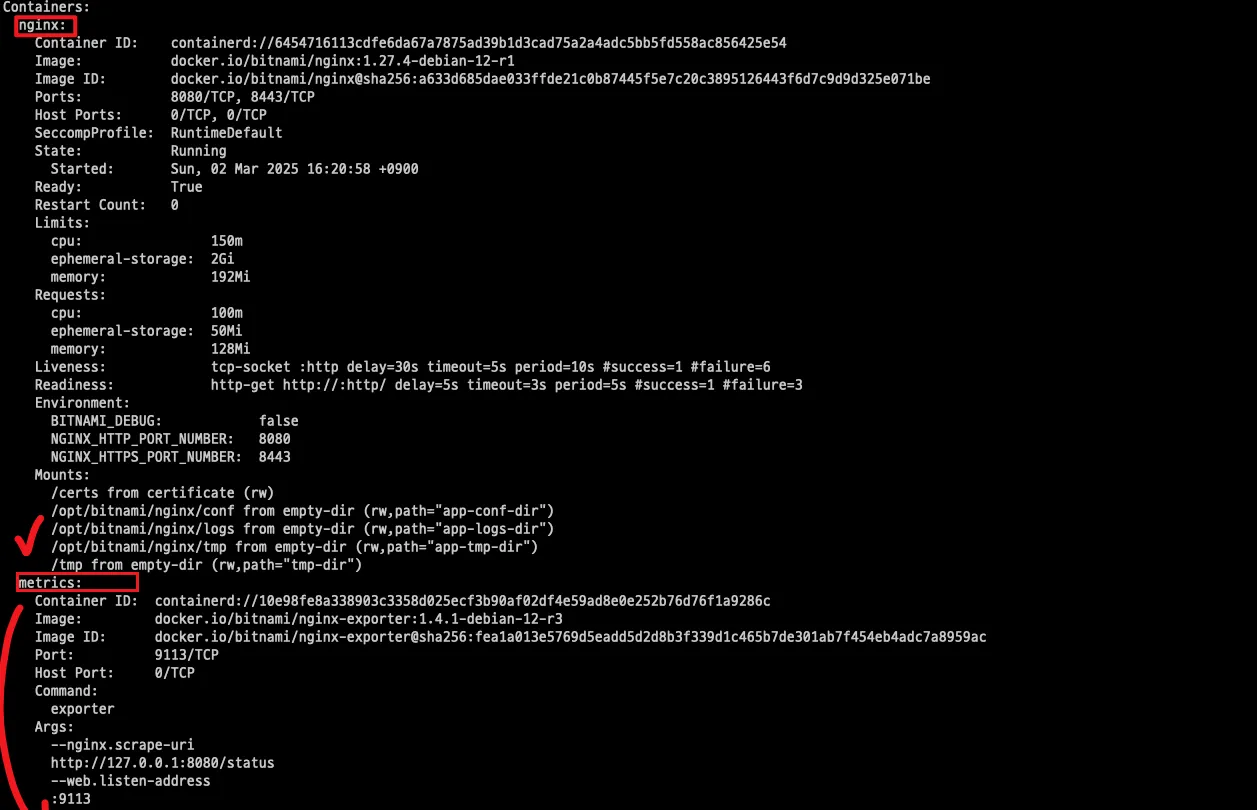
또한 프로메테우스 웹서버에서 서비스 엔드포인트가 추가된 것을 확인할 수 있습니다.
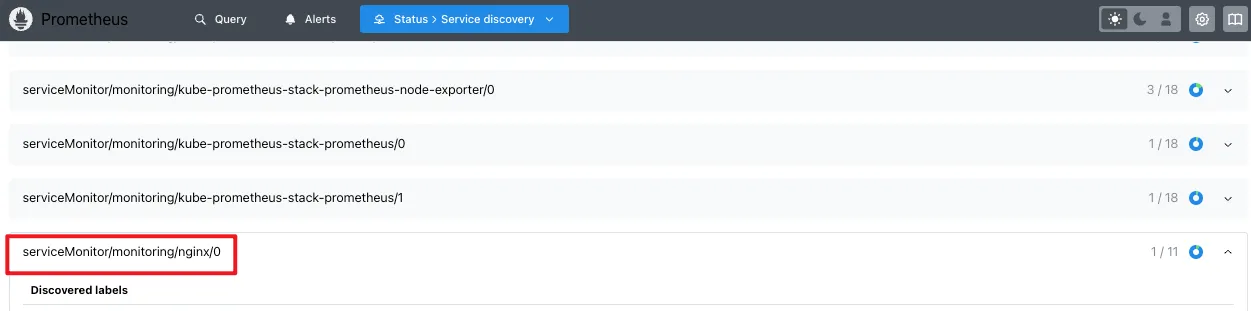

서비스 디스커버리에 등록되었다는 것은 어쨌거나 프로메테우스의 config가 변경되었고, config가 패치가 되었다는 것인데, 이는 누가 어떻게 한것이느냐 하면 위에서 설명한 config-reloader가 동적으로 config를 수행한 것을 알 수 있습니다.
아래 파드를 살펴보면 어떤 config가 적용되었는지 위치를 알수 있습니다.

# config 변경 내용 살펴보기
kubectl krew install view-secret
kubectl get secret -n monitoring
kubectl view-secret -n monitoring prometheus-kube-prometheus-stack-prometheus
kubectl view-secret -n monitoring prometheus-kube-prometheus-stack-prometheus | zcat | more
kubectl view-secret -n monitoring prometheus-kube-prometheus-stack-prometheus | zcat | grep nginx -A 20

config가 .gz 형태로 압축되었기 때문에 zcat으로 읽어줘야 합니다.

이제 실제로 어떠한 메트릭이 수집됬는지 확인해 보도록 합니다.
# [운영서버 EC2] 메트릭 확인 >> 프로메테우스에서 Target 확인
## nginx sub_status url 접속해보기
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath="{.items[0].status.podIP}")
curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인 : metrics 컨테이너 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl stern deploy/nginx
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done내부 IP로 curl을 날릴 것이기 때문에 운영서버에서 수행해줍니다.


프로메테우스 Query 메뉴에서 nginx_up 메트릭을 조회하여 확인해 봅니다.

replicas 를 2로 늘려 실시간으로 조회되는 것을 확인해 봅니다.
# nginx scale out : Targets 확인
kubectl scale deployment nginx --replicas 2
# 쿼리 Table -> Graph
nginx_up
sum(nginx_up)
nginx_http_requests_total
nginx_connections_active
쿼리문에 sum 집계함수를 작성하지 않으면 그래프 상으로는 눈에 띄지 않는 걸 볼 수 있었을 겁니다. 따라서 어떤 쿼리문을 사용하는 지가 모니터링을 하는 데 있어서 굉장히 중요한 것을 알 수 있습니다.
PromQL (Prometheus Query Language)
Prometheus에서 시계열 데이터를 조회하고 분석할 수 있도록 설계된 쿼리 언어로, 실시간 모니터링 및 경고 생성에 활용됩니다.
프로메테우스 메트릭 종류 (4종) : Counter, Gauge, Histogram, Summary - Link Blog
- 게이지 Gauge : 특정 시점의 값을 표현하기 위해서 사용하는 메트릭 타입, CPU 온도나 메모리 사용량에 대한 현재 시점 값
- 카운터 Counter : 누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간 별로 변화(추세) 확인, 계속 증가 → 함수 등으로 활용
- 서머리 Summary : 구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
- 히스토그램 Histogram : 사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도를 측정 → 함수로 측정 포맷을 변경
다양한 PromQL 예제를 공부하여 Syntax를 익히면 좋습니다. Docs Operator Example
# 산술 이진 연산자 : + - * / * ^
node_memory_Active_bytes
node_memory_Active_bytes**/1024**
node_memory_Active_bytes**/1024/1024**
# 비교 이진 연산자 : = = ! = > < > = < =
nginx_http_requests_total
nginx_http_requests_total > 100
nginx_http_requests_total > 10000
# 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
kube_pod_status_ready
kube_pod_container_resource_requests
kube_pod_status_ready == 1
kube_pod_container_resource_requests > 1
kube_pod_status_ready == 1 or kube_pod_container_resource_requests > 1
kube_pod_status_ready == 1 and kube_pod_container_resource_requests > 1또한 PromQL 에 적절한 집계함수를 사용하여 자체적으로 통계적 데이터를 만들어 낼 수 있습니다.
Aggregation Operators 집계 연산자 - Link
sum(calculate sum over dimensions) : 조회된 값들을 모두 더함min(select minimum over dimensions) : 조회된 값에서 가장 작은 값을 선택max(select maximum over dimensions) : 조회된 값에서 가장 큰 값을 선택avg(calculate the average over dimensions) : 조회된 값들의 평균 값을 계산group(all values in the resulting vector are 1) : 조회된 값을 모두 ‘1’로 바꿔서 출력stddev(calculate population standard deviation over dimensions) : 조회된 값들의 모 표준 편차를 계산stdvar(calculate population standard variance over dimensions) : 조회된 값들의 모 표준 분산을 계산count(count number of elements in the vector) : 조회된 값들의 갯수를 출력 / 인스턴스 벡터에서만 사용 가능count_values(count number of elements with the same value) : 같은 값을 가지는 요소의 갯수를 출력bottomk(smallest k elements by sample value) : 조회된 값들 중에 가장 작은 값들 k 개 출력topk(largest k elements by sample value) : 조회된 값들 중에 가장 큰 값들 k 개 출력quantile(calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions) : 조회된 값들을 사분위로 나눠서 (0 < $ < 1)로 구성하고, $에 해당 하는 요소들을 출력
사용 예제
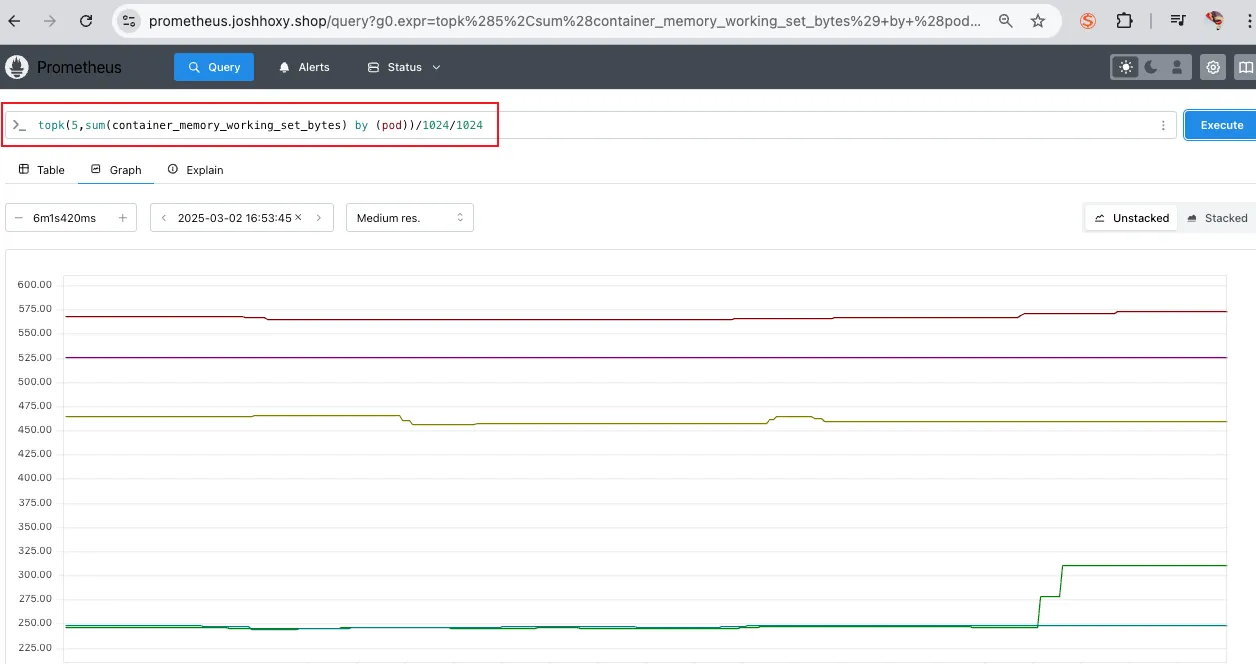
- topk(5, avg by (pod) (rate(container_cpu_usage_seconds_total[5m])))
- topk(5, avg by (pod) (container_memory_usage_bytes))
- sum(rate(http_request_duration_seconds_bucket{le="0.5"}[5m])) / sum(rate(http_request_duration_seconds_count[5m])) * 100
- avg by (instance) (rate(node_network_transmit_bytes_total[5m]))
Grafana
위 에서 Prometheus 의 그래프를 사용해보면서 느끼셨겠지만 모니터링 대시보드로서 사용하기에는 한계가 있는 것을 확인하셨을 거라 생각합니다. 따라서 Prometheus 에서 데이터를 가져와 시각화 해주는 대표적 OTel 툴인 그라파나에 대해서 소개하겠습니다.
- TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등)
- Grafana는 오픈소스 데이터 시각화 및 모니터링 툴로, Prometheus, InfluxDB, Elasticsearch, MySQL 등 다양한 데이터 소스를 연동하여 대시보드 형태로 데이터를 시각화할 수 있습니다.
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않습니다. → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용. 그라파나에 MySQL Lite DB를 사용하긴 하지만 해당 디비에서는 메트릭을 저장하지 않고 설정 및 얼럿등에 대한 그라파나 자체 데이터를 저장합니다.
Grafana 기능
그라파나의 다양한 메뉴 및 기능은 몇번 탐색하다 보면 금방 익힐 수 있을 정도로 사용자 친화적이고 시각적인 정보를 제공합니다.

그라파나 관리자로 접속하여 왼쪽 페이지를 살펴보면 다음과 같은 메뉴들이 있습니다.
- Bookmarks – 자주 사용하는 대시보드나 탐색 페이지를 북마크하여 빠르게 접근할 수 있도록 저장하는 기능.
- Starred – 중요하거나 자주 사용하는 대시보드를 별(★) 표시하여 즐겨찾기로 등록하고 쉽게 찾을 수 있도록 관리하는 기능.
- Dashboards – 사용자가 생성한 모든 대시보드를 관리하고, 새로운 대시보드를 생성하거나 수정할 수 있는 메뉴.
- Explorer – 실시간 데이터 탐색 및 분석을 위한 기능으로, 특정 쿼리를 실행하여 데이터를 조회하고 시각화할 수 있음.
- Alerting – 특정 조건이 충족될 때 경고를 생성하고 Slack, Email, PagerDuty 등으로 알림을 전송하는 기능을 설정하는 메뉴.
- Connections – Prometheus, Loki, MySQL, Elasticsearch 등 다양한 데이터 소스를 Grafana와 연결하고 설정하는 메뉴.
- Administration – 사용자 및 권한 관리, 데이터 소스 설정, 조직 설정, 플러그인 설치 등 Grafana의 전반적인 관리를 담당하는 메뉴.
Grafana Connection
그라파나가 원천 데이터를 수집하기 위해서는 connection 설정이 반드시 되어있어야 합니다. 이번 실습에서는 프로메테우스와 연동이 되어있기 때문에 해당 설정을 살펴보겠습니다.
# 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus

임시 파드를 하나 생성해서 해당 서비스(프로메테우스)가 정상적으로 작동하는 지 확인해 봅니다.
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
# 삭제
kubectl delete pod netshoot-pod
Grafana 대시보드 생성(Import)
Connection이 정상적으로 연동된 것을 확인했으면 메트릭을 조회할 수 있는 걸 확인할 수 있습니다. 이제 이러한 데이터를 가공하여 대시보드를 생성해서 모니터링 시각도구를 만들어봅니다.
그라파나는 오픈소스로서 다양한 커뮤니티 유저들이 자신들이 만든 대시보드를 공유하고 공식적으로 기본제공하는 대시보드가 있어 이를 재활용하여 대시보드를 더 빠르게 구축할 수 있습니다.
기본 대시보드
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- K8S / CR / Cluster, Node Exporter / Use Method / Cluster
- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 력입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭

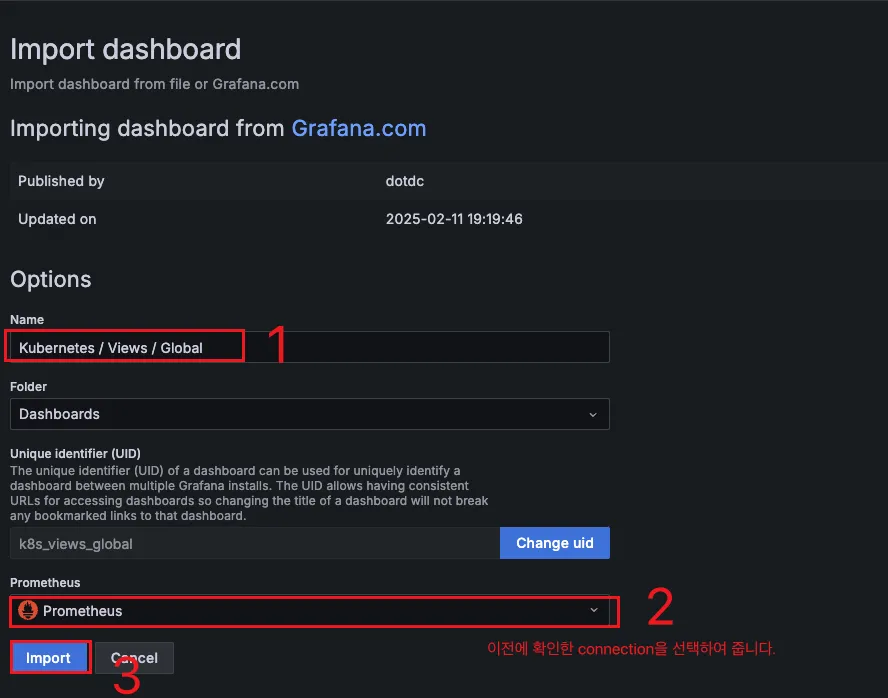
Import 한 화면

대시보드 PromQL 수정하기
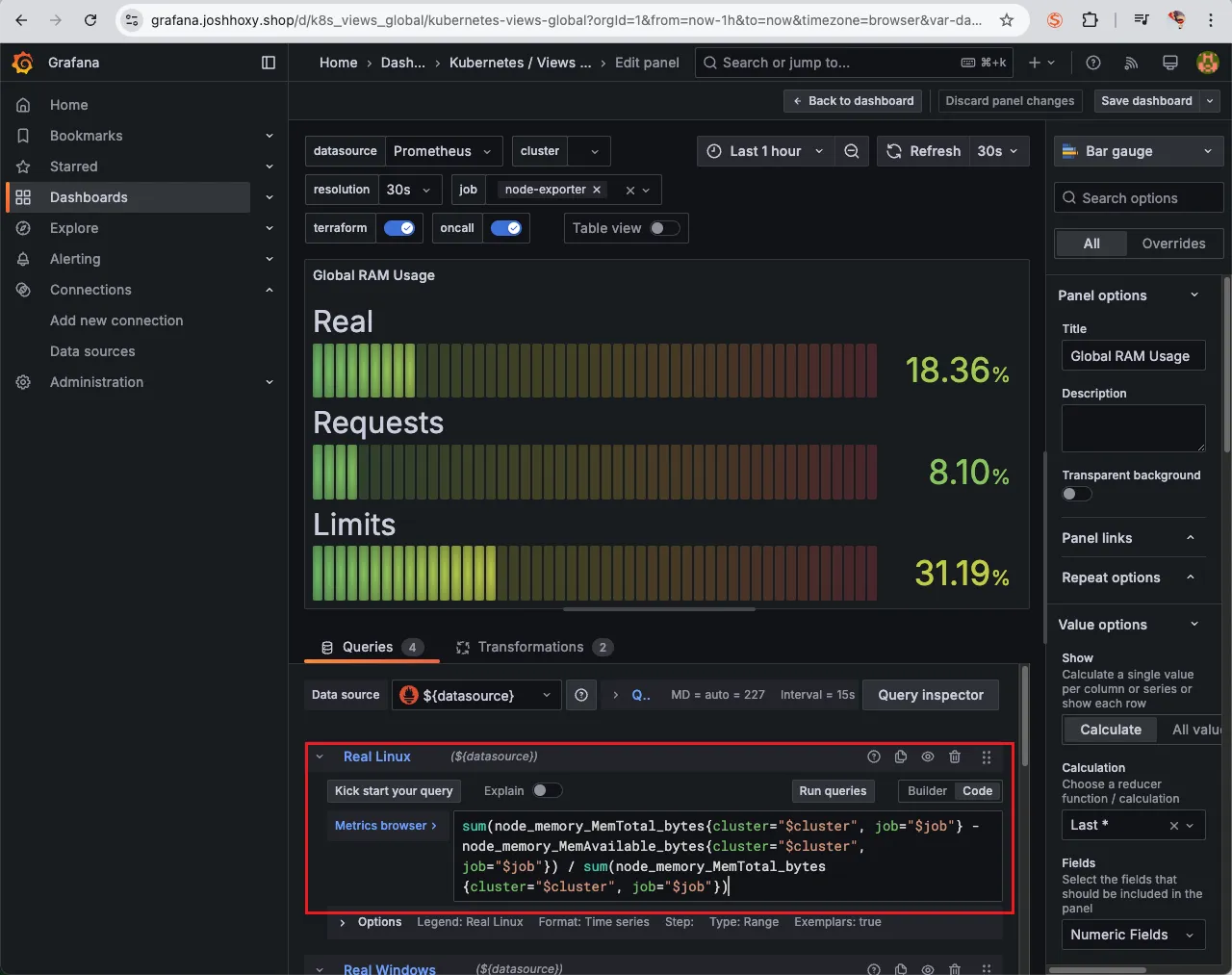
Import 한 대시보드가 한 번에 본인의 needs에 만족하면 정말 좋겠지만 대부분 본인의 SLA SLO에 따라 수정해야할 일이 있고 Unit 등의 차이로 PromQL을 다시 작성해야할 필요가 있습니다.
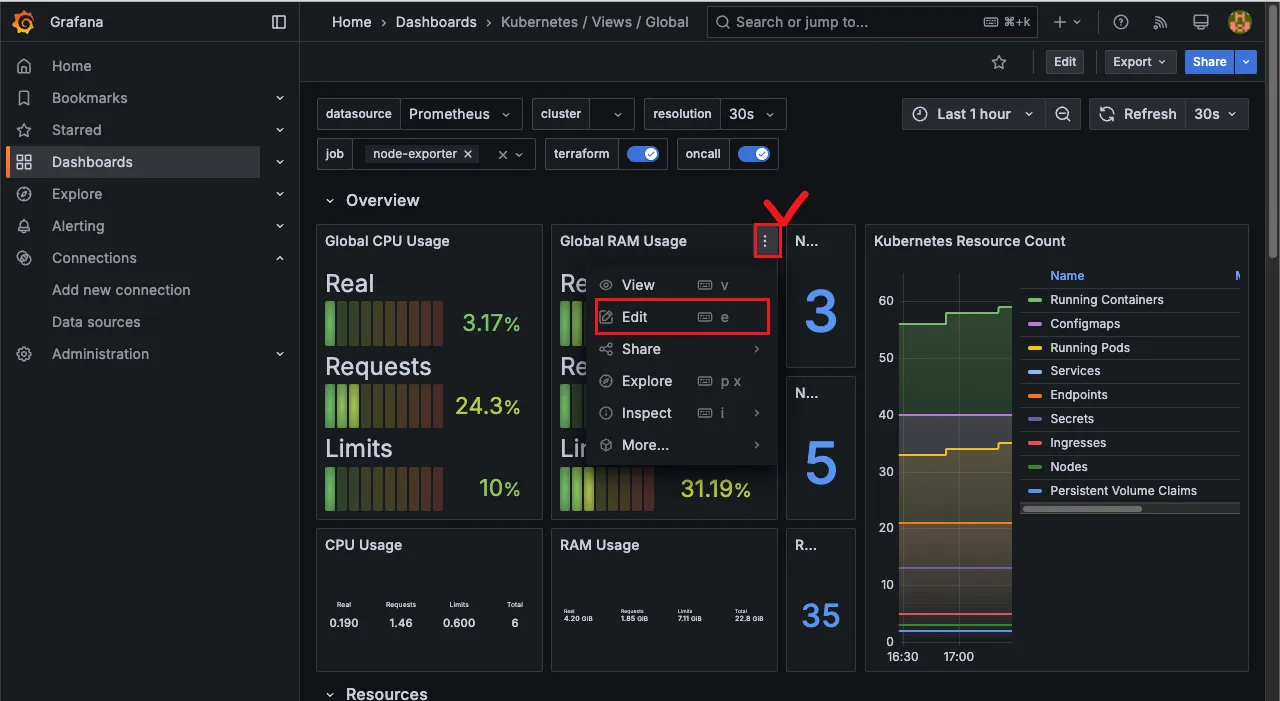
그럴 땐 다음과 같이 edit 창을 띄운 후 아래 PromQL을 본인이 필요한 대로 조정하여 커스텀하여 줘야 합니다.
Grafna 대시보드 수정
상단 네임스페이스와 파드 정보 필터링 출력되게 수정해보기
오른쪽 상단 Edit → Settings → Variables 아래 namesapce, pod 값 수정 ⇒ 수정 후 Save dashboard 클릭합니다.


namespace 경우 : kube_pod_info 로 수정
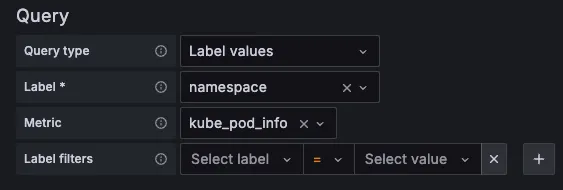
namespace 오른쪽 Showing usages for 클릭 시 → 맨 하단에 pod variable 가 namespace 를 하위에 종속? 관계 확인

이 외에 실제 EKS 운영에 도움이 될만한 대시보드에 대해서 공유드립니다.
- [Node Exporter Full] 1860
- [Node Exporter for Prometheus Dashboard based on 11074] 15172
- [kube-state-metrics-v2] 13332 클릭 - 링크
- [Amazon EKS] AWS CNI Metrics 16032 - 링크
Grafana Alert
그라파나는 Alert 기능을 통해 모니터링 경보 발생 시 슬랙, 이메일, Amazon Connect 등 다양한 엔드포인트를 통해 전파가 가능합니다.
※ Release NOTE ※
그라파나 9.4 버전이 2월 28일 출시 - 링크 ⇒ Alerting 기능이 강화되었고, 이미지 알람 기능도 제공 - 링크
그라파나 9.5 버전이 Alerting 기능 업데이트 - 링크

Grafana Alert 구성
본인의 슬랙 워크스페이스를 개설해서 웹훅 URL을 하나 만들어 줍니다.
그 후 contact points에 어디에 게시할지 엔드포인트를 설정해줍니다.
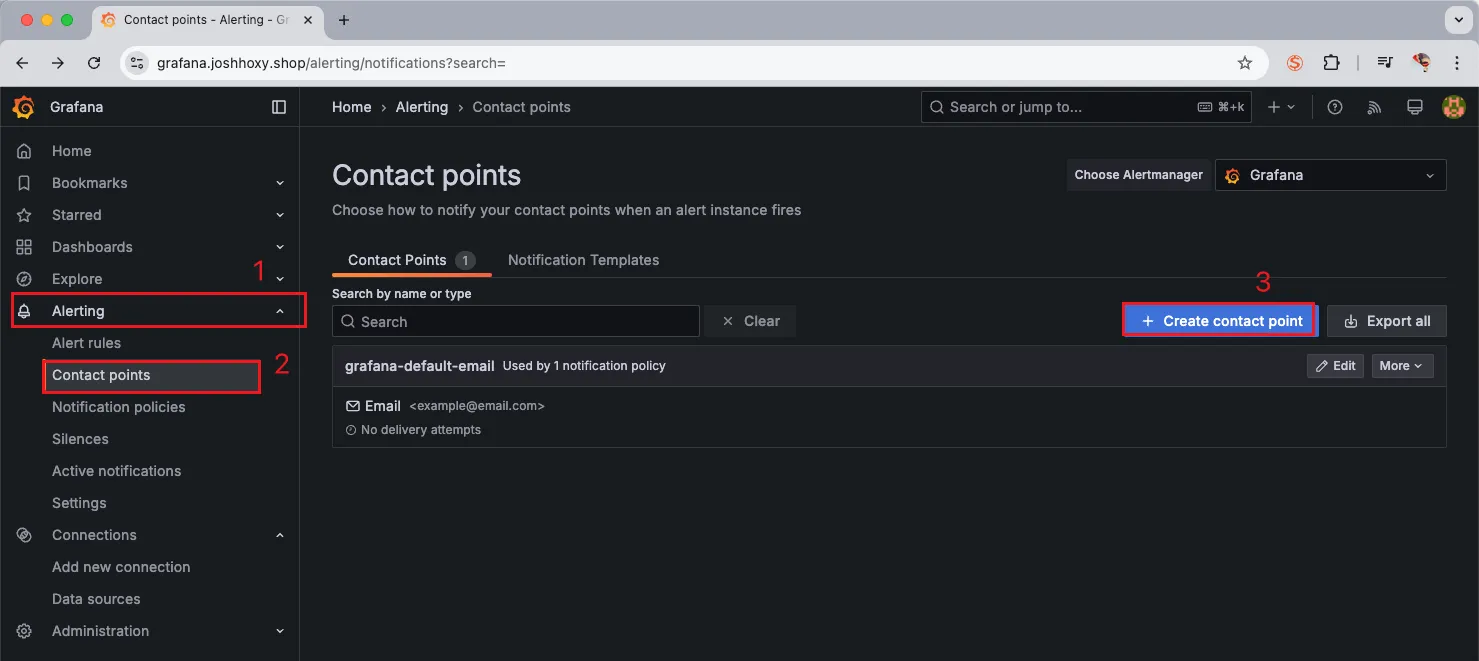


얼럿은 기본적으로 텍스트 형식 기반으로 오는데 이를 그래프와 같은 이미지로 메세지를 전달하도록 렌더링 하는 방법에 대해서는 다음 포스팅에서 작성해 보도록 하겠습니다.
Appendix
Amazon EKS Optimized Amazon Linux 2023 AMI 특징 및 장점 (3가지)
- 최적화된 성능: EKS 환경에 맞게 커널, 컨테이너 런타임, kubelet 등의 구성 요소들이 사전 구성 및 최적화되어 있어, Kubernetes 워크로드 실행 시 뛰어난 성능을 제공합니다.
- 향상된 보안: Amazon Linux 2023을 기반으로 최신 보안 패치 및 업데이트가 적용되어 있어, 컨테이너 환경의 보안을 강화하고 잠재적인 위협으로부터 보호합니다.
- 간편한 사용: EKS 클러스터 구축 및 관리를 간소화할 수 있도록 AMI가 제공되므로, 사용자는 복잡한 설정 과정 없이 빠르게 클러스터를 구성하고 워크로드를 배포할 수 있습니다.
'AWS > EKS' 카테고리의 다른 글
| EKS Security - ECR Enhanced Scanning (0) | 2025.03.16 |
|---|---|
| EKS Autoscaling - 3 (Karpenter) (0) | 2025.03.09 |
| EKS Autoscaling - 2 (Node level) (0) | 2025.03.09 |
| EKS Autoscaling - 1 (Pod level) (0) | 2025.03.08 |
| EKS Basic Concepts (0) | 2025.02.08 |



