
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- xfs_quota
- EBS
- ebs 마운트
- MFA 분실
- 볼륨추가
- Authenticator
- 테라폼 맥
- 테라폼 설치
- Mac Terraform
- 리눅스 시간대
- AWS EBS
- 테라폼 자동완성
- epxress-generator
- Terrafrom
- 리눅스
- 테라폼 캐시
- /etc/fstab 설정
- 컨테이너 터미널 로그아웃
- 디스크 성능테스트
- AWS
- EC2
- 텔레메트리란
- docker -i -t
- 볼륨 연결
- MFA 인증
- docker 상태
- 컨테이너 터미널
- EBS 최적화
- ebs 재부팅
- /etc/fstab 뜻
- Today
- Total
I got IT
Prometheus 기본 본문
❓프로메테우스란

Prometheus는 **CNCF(Cloud Native Computing Foundation)**가 후원하는 오픈소스 모니터링 및 알림 시스템입니다. 시계열(Time-series) 데이터 수집 및 분석을 주 목적으로 하며, Kubernetes와 같은 클라우드 네이티브 환경에서 성능 모니터링 및 메트릭 수집을 위해 널리 사용됩니다.
특징
- 시계열 데이터를 처리 (Time-series DB == TSDB)
- 주로 CPU, MEM 등 시스템 지표 수집에 사용됨
- CNCF 오픈프로젝트. 다른 CNCF 오픈소스 서비스와 호환이 좋음 (Istio, Jaeger).
- 시각화 도구인 Grafana 와 연동하는 유스케이스가 많음
장점
- 풀링 방식 Pulling.
- 모니터링 타겟이 프로메테우스의 YAML 설정값을 통해 Discovery 됨
- 서비스디스커버리와 호환하여 타겟이 변동되도 자동으로 등록하는 프로세스 구현 가능 (이는 풀링 구조이기때문에 가능)
- PromQL 이라는 자체 쿼리를 이용해 explore 용이
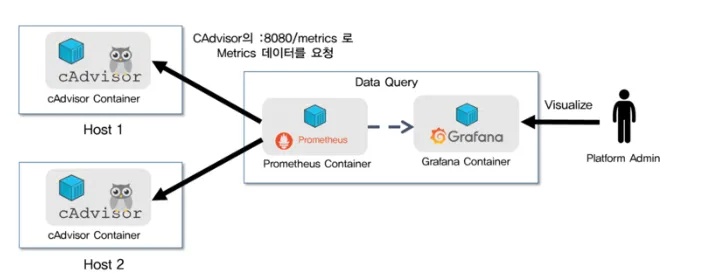
Prometheus 아키텍처

- 메트릭 수집 (Scraping)
- Prometheus는 Kubernetes 클러스터 및 여러 Exporter(Node Exporter, cAdvisor 등)로부터 메트릭을 주기적으로 가져옴.
- 이 과정은 Pull 방식으로 동작하며, Prometheus가 대상 시스템의 /metrics 엔드포인트에서 데이터를 스크랩함.
- Prometheus는 다양한 Exporter(예: Kubernetes 노드, 애플리케이션, 데이터베이스 등)로부터 메트릭을 가져옴.
- 데이터 저장 (Storage)
- 수집된 메트릭 데이터는 Prometheus 내부의 시계열(Time-Series) 데이터베이스에 저장됨.
- 기본적으로 **로컬 저장소(TSDB, Time Series Database)**를 사용하지만, 장기 저장을 위해 외부 저장소(ex: Thanos, Cortex)와 연동할 수도 있음.
- 데이터 시각화 (Visualization)
- 저장된 메트릭 데이터는 Grafana와 같은 시각화 도구를 사용하여 대시보드에서 모니터링할 수 있음.
- Grafana는 Prometheus 데이터 소스를 연동하여 메트릭을 그래프 형태로 표시함.
- 알람 설정 및 이벤트 전송 (Alerting)
- Prometheus는 Alertmanager를 사용하여 특정 임계값을 초과하는 이벤트를 감지하고 알림을 발생시킴.
- Alertmanager는 Slack, Webhooks, PagerDuty 등의 알림 시스템과 연동되어 운영자가 문제를 즉시 확인할 수 있도록 함.
풀링(pulling) 방식
프로메테우스를 이해하기 위해서는 풀링 구조를 잘 알아야합니다. Pulling 에서는 수집하려는 대상을 source로 표현하지 않고 target 이라고 표현합니다.
target system에서 메트릭을 수집해오는 방식. 타겟 시스템은 exporter를 실행하여 메트릭을 뽑아냅니다.
보통은 소스에서 푸시하는 방식으로 지표를 수집하는데 프로메테우스는 풀링방식을 사용합니다.
푸시 방식은 모니터링 대상이 가변직이거나 오토스케일링할때 유리합니다.
하지만 풀링방식의 경우 모니터링 대상이 늘어나거나 IP가 변경되는 경우에는 찾아갈 주소를 모르니까 불리합니다. 이를 보완하기 위해서 Service Discovery라는 기능을 사용하는 것입니다.
풀링(pulling) 방식의 장점
- 자동 서비스 디스커버리 가능
- Kubernetes 환경에서 새로운 Pod이나 서비스가 추가될 때, 서비스 디스커버리(Service Discovery) 를 통해 자동으로 탐색하여 모니터링 가능
- Prometheus는 Kubernetes의 Pod, Service, Endpoints 정보를 조회하여 메트릭을 수집
- 중앙 집중형 모니터링 (Prometheus 서버에서 일괄 관리)
- 데이터 수집 로직을 Prometheus 서버에서 통합 관리하여 클라이언트 애플리케이션의 부담을 줄일 수 있음
- 애플리케이션에서 직접 Push할 필요가 없고, Prometheus가 적절한 간격으로 요청
- 유연한 데이터 조회 (Scraping 인터벌 설정 가능)
- Prometheus는 각 대상(Target)에 대한 스크랩 간격을 개별적으로 설정 가능
- 예: 중요한 서비스는 5초마다, 비중요 서비스는 1분마다 데이터를 수집
- 네트워크 부하 최소화
- 필요할 때만 데이터를 가져오기 때문에 불필요한 네트워크 트래픽을 줄일 수 있음
- Push 방식과 비교하면 클라이언트가 데이터를 지속적으로 전송하지 않아도 됨
- 데이터 무결성 및 중복 방지
- Prometheus 서버가 직접 메트릭을 수집하므로, 중복 데이터 문제를 방지할 수 있음
- Push 방식에서는 동일한 데이터가 여러 번 전송될 가능성이 있음
Service Discovery
클라우드에서 운영을 하게되면 AutoScale, 파드 down 및 재생성 등으로 인해 IP나 Port가 변경되는 경우가 많음. 이때 이를 하나의 시스템에서 서비스를 등록 및 해제 등의 구성을 관리하는 것을 service discovery라 합니다.
Client-Side discovery, Server-Side discovery 형태로 나뉨. 보통 Server-Side discovery 많이 사용합니다.

Exporter
- 메트릭 수집하는 애플리케이션
- 프로메테우스는 다양한 exporter를 지원하고 통합하는 기능을 제공합니다.
- 지원되는 exporter는 공식문서 참고 🔗
Retrieval
Exporter에 주기적으로 요청하는 주체. Prometheus의 컴포넌트 중 하나
저장 로직 ❗
프로메테우스는 기본적으로 뒷단에 별도의 DB, 스토리지를 사용하지 않고 데이터를 로컬에 저장한다. 따라서 스케일링이 불가능하다는 단점이 있습니다. 또한 대상 시스템이 늘어날수록 저장공간을 많이 차지한다.
따라서 보통 주기적으로 데이터를 정리하는 작업을 합니다.. → 영구저장X
Prometheus 데이터 구조

데이터 이름: Metrics를 구분하기 위한 고유한 이름.
라벨: 동일한 데이터에서 종류를 구분하기 위한 식별자. 예를 들면 같은 폰이라도 각자 고유 시리얼넘버가 있듯이
Value: 데이터 값. Scalar 라고도 함. 예를 들면 메모리 사용률의 지표의 경우 메모리 사용률은 ‘데이터 이름’ 이고 그 수치는 Value (Scalar)인 것
Prometheus의 데이터 보관
위에서 말했듯 프로메테우스는 데이터를 In-Memory로 저장하고 있다가 로컬 filesystem에 주기적으로 flush 해준다.
방법은 아래와 같다
- start 시 명령인자 전달
ex)prometheus --config.file=prometheus.yml --storage.tsdb.retention.time=365d - service 파일 수정. 가용성을 위해 이 옵션을 권장
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus/ \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries \
--web.external-url=http://34.89.26.156:9090 \
--storage.tsdb.retention.time=1y # 추가
[Install]
WantedBy=multi-user.target- 컨테이너 환경의 경우 (helm 사용 가정)
prometheus:
prometheusSpec:
## How long to retain metrics
##
retention: 10d
로컬 저장소 설정

➕ 데이터 영구보관 설정 시
프로메테우스에서 수집된 데이터는 2시간 정도 메모리에 저장된 후, 로컬 디스크로 덤프되어 저장됩니다. 이 데이터를 타노스 에이전트가 수집하여 외부 스토리지에 저장합니다. 외부 스토리지는 Ceph와 같은 분산형 파일 시스템 혹은 Google Cloud Storage, AWS S3와 같은 클라우드 스토리지를 사용합니다.
데이터 파일
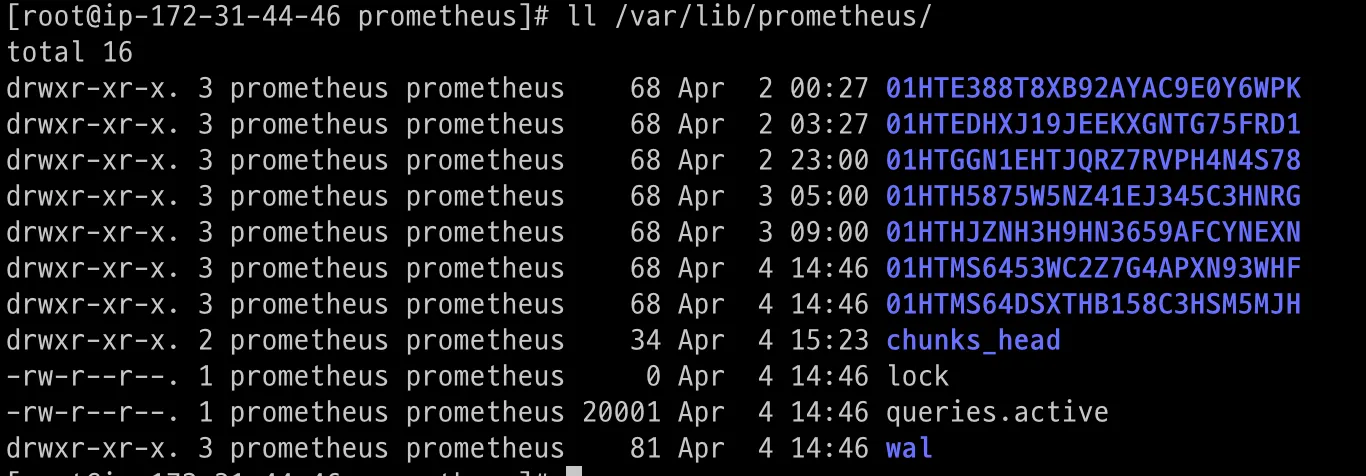
프로메테우스의 데이터 종류는 크게 두가지 입니다 🔗
- 로컬 파일 시스템 : 일반적인 chunk 블록 파일
- 인메모리 : WAL (Write Ahead Logging) 파일1 & 인메모리 버퍼
prometheus의 Memory & Disk
storage.local.target-heap-size = 2GiB 가 default 값이고 이는 물리메모리의 2/3 수치이다. 해당 힙사이즈는 물리메모리의 최소 2/3은 되어야 한다.
프로메테우스의 메모리
메모리에서 데이터 2시간 동안 보관 → 로컬 disk 로 저장하는 싸이클을 가지고 있습니다.
The retention and long-term storage in Prometheus has almost no effect on RSS needed to run Prometheus. Prometheus only needs memory (RSS) to manage the current 2 hours of data. After 2 hours, everything in memory is flushed to disk and mapped-in using a technique called "mmap". This means disk blocks are virtually mapped into memory (VSS). Then the Linux kernel uses page cache to manage what data is loaded. You can have terabytes of data in the TSDB and it only uses a small amount of RSS to manage the mappings.
즉 WAL에서는 최소 2시간 동안 쌓이다가 chunk로 저장

WAL (Write Ahead Log)
- WAL은 "Write-Ahead Log"의 약자로, 데이터가 실제 저장소에 기록되기 전에 로그에 먼저 기록되는 매커니즘
- 메트릭 복구 (Crash Recovery)를 위함
- 메모리와 가장 가까움
Chunk
- Chunk는 시계열 데이터를 효율적으로 저장하고, 쿼리 성능을 높이기 위해 사용되는 데이터 블록이다.
- 각 시계열 데이터는 여러 개의 Chunk로 나뉘어 저장됩니다. 일반적으로 하나의 Chunk는 몇 시간 또는 몇 일 동안의 데이터를 포함한다.
- --storage.tsdb.min-block-duration 과 --storage.tsdb.max-block-duration 옵션 설정으로 크기를 지정할 수 있다.
- 구조: block chunk ) chunks, metadata, index, 기타 관리파일

- 청크의 크기가 클수록 인덱싱이 적어짐 → 쿼리(select) 성능 떨어질 수 있음
※ 참고: 프로메테우스의 --storage.tsdb.min-block-duration 값은 최소 2
Prometheus의 --storage.tsdb.min-block-duration 설정은 TSDB(Time Series Database)의 블록 크기를 조정하는 파라미터입니다. 이 값은 기본적으로 2시간으로 설정되어 있습니다. 이는 블록의 최소 지속 시간을 나타내며, Prometheus는 데이터가 이 기간 동안 수집되면 블록을 생성합니다.
기본 설정:
- -storage.tsdb.min-block-duration=2h
그러나 Prometheus에서는 이 값을 2시간 미만으로 설정할 수 없습니다. 이는 Prometheus의 설계 및 성능 최적화를 위해 설정된 최소 값입니다. 너무 작은 블록 크기를 사용하면 성능에 부정적인 영향을 미칠 수 있습니다. 너무 자주 블록을 생성하면 성능 저하와 자원 낭비를 초래할 수 있기 때문입니다.
공식 문서 참고
Prometheus 공식 문서에 따르면, 최소 블록 크기는 2시간으로 고정되어 있으며, 이보다 작은 값을 사용할 수 없습니다. 다음은 관련 문서의 내용입니다.
설정 가능한 값 범위:
- 최소값: 2시간
- 기본값: 2시간
예시:
prometheus --storage.tsdb.min-block-duration=2h
요약:
Prometheus의 --storage.tsdb.min-block-duration 값을 2시간보다 낮게 설정할 수 없습니다. 이는 성능 및 효율성을 위해 Prometheus가 설정한 최소 값입니다. Prometheus를 최적의 성능으로 운영하기 위해서는 이 값을 준수하는 것이 좋습니다.