
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Mac Terraform
- ebs 재부팅
- 테라폼 캐시
- 테라폼 맥
- 컨테이너 터미널 로그아웃
- EC2
- 테라폼 설치
- /etc/fstab 설정
- Authenticator
- AWS
- 디스크 성능테스트
- EBS
- 텔레메트리란
- Terrafrom
- epxress-generator
- 볼륨추가
- docker 상태
- 리눅스 시간대
- AWS EBS
- 리눅스
- docker -i -t
- MFA 인증
- 컨테이너 터미널
- xfs_quota
- 테라폼 자동완성
- /etc/fstab 뜻
- ebs 마운트
- EBS 최적화
- 볼륨 연결
- MFA 분실
- Today
- Total
I got IT
EKS Upgrades 본문
※ 해당 글은 AWS Workshop - Amazon EKS Upgrades: Strategies and Best Practices 과 가시다님의 AEWS 스터디 내용을 참고하여 작성하였습니다.
EKS Upgrades
들어가며
K8s 업그레이드는 보안 취약점과 버그를 해결하고, 최신 기능을 도입해 클러스터 안정성과 성능을 향상시킵니다.
지원되는 버전을 유지함으로써 지속적인 기술 지원과 호환성을 보장할 수 있습니다.
또한 k8s 의 신규 기능은 끊임 없이 생겨나고 있으며 MSA 의 디팩토가 된 k8s 를 기반으로 다양한 새로운 오픈소스 및 개발 방법론이 진화하기 때문에 k8s 업그레이드를 f/u 하는 것은 굉장히 중요합니다.
K8S 업그레이드
EKS 업그레이드를 진행하기 전에 관리형 서비스가 아닌 자체 구축형 K8S 클러스터에서 어떤 방식으로 업그레이드를 수행하는 지 살펴보고 EKS에서 업그레이드를 진행하는 것과 어떤 차이가 있는 지 알아보도록 하겠습니다.
K8S Release cycle


- 정식 릴리스는 연 3회 (약 4개월 주기) 배포됩니다.
- 각 릴리스는 최대 1년(12개월) + 1개월 유예 기간, 총 14개월간 지원됩니다.
- 이 기간 동안에는 보안 패치 및 버그 수정이 포함된 Patch 릴리스가 제공됩니다
K8S Version Skew Policy 🔗
쿠버네티스는 다양한 컴포넌트로 구성되어 있습니다. 이때 컴포넌트 간 버전이 상이할 수 있습니다.

버전 스큐(version skew)는 쿠버네티스의 다양한 컴포넌트 간에 지원되는 최대 버전 차이를 의미합니다. 각 컴포넌트는 특정 버전 차이 내에서만 호환되며, 이를 초과하면 시스템의 안정성과 기능에 문제가 발생할 수 있습니다.
버전 스큐는 컴포넌트 간 그 차이 정도가 다릅니다 따라서 컴포넌트 별로 다른 버전을 사용할 때 이 버전 스큐를 잘 확인해서 업그레이드 여부를 결정해야 합니다.
다음은 각 주요 컴포넌트의 버전 스큐 예시입니다.
- kube-apiserver : HA apiserver 경우 newest 와 oldest 가 1개 마이너 버전 가능
- newest
kube-apiserveris at 1.32 - other
kube-apiserverinstances are supported at 1.32 and 1.31
- newest
- kubelet/kube-proxy : kubelet 는 apiserver 보다 높을수 없음. 추가로 apiserver 보다 3개 older 가능
kube-apiserveris at 1.32kubeletis supported at 1.32, 1.31, 1.30, and 1.29- 만약 apiserver 가 HA로 1.32, 1.31 있다면 kubelet 는 1.32는 안되고, 1.31, 1.30, 1.29 가능
- kube-controller-manager, kube-scheduler, and cloud-controller-manager : skip
- kubectl : one minor version (older or newer) of
kube-apiserverkube-apiserveris at 1.32kubectlis supported at 1.33, 1.32, and 1.31 (kubectl 만 유일하게 kube-apiserver 보다 높은 버전이 가능)
K8S 업그레이드 전략
쿠버네티스 업그레이드 전략은 크게 두 가지 방식으로 나눌 수 있습니다. 각각의 방식은 운영 환경과 서비스 특성에 따라 선택됩니다.
1. In-place 업그레이드 (롤링 업그레이드)
기존 클러스터 내에서 컨트롤 플레인과 워커 노드를 순차적으로 업그레이드하는 방식입니다.
장점:
- 별도의 인프라를 새로 구성할 필요가 없습니다.
- 비교적 리소스 절약적이며, 운영 중인 클러스터 환경을 유지할 수 있습니다.
단점:
- 업그레이드 도중 문제가 생기면 전체 클러스터에 영향을 줄 수 있습니다.
- 롤백이 어려울 수 있으며, 신중한 사전 준비가 필요합니다.
2. Blue/Green 업그레이드 (새 클러스터 전환 방식)
업그레이드된 버전의 새 클러스터를 생성하고, 기존 클러스터에서 트래픽을 점진적으로 전환하는 방식입니다.
장점:
- 기존 클러스터는 그대로 두고 새로운 환경에서 테스트 후 전환할 수 있어 안정성이 높습니다.
- 문제가 발생하더라도 원래 클러스터로 쉽게 롤백이 가능합니다.
단점:
- 이중 클러스터를 운영해야 하므로 비용과 리소스가 더 들 수 있습니다.
- 클러스터 간 트래픽 스위칭이나 데이터 마이그레이션 작업이 추가로 필요합니다.
운영 안정성이 중요한 프로덕션 환경에서는 Blue/Green 전략을, 개발·테스트 환경이나 리소스가 제한된 상황에서는 In-place 전략을 선택하는 경우가 많습니다.
다음과 같은 의사결정 트리를 참고하여 본인의 환경에 맞는 배포전략이 어떤 것인지 참고 하면 좋을듯 합니다.

K8S Upgrade 과정 (In-place)
다음은 일반적인 K8S(바닐라쿠버네티스) 클러스터 업그레이드 과정입니다. 클러스터 업그레이드는 컨트롤 플레인, 데이터 플레인 순으로 진행합니다. 이하 컨트롤 플레인은 CP, 데이터 플레인은 DP라고 지칭하겠습니다.
다음 과정은 In-place 전략을 선택하고 1.28 부터 1.30 까지 업그레이드 하는 시나리오의 과정입니다.

0️⃣ 버전 호환성 검토
- K8S(kubelet, apiserver..) 1.30 요구 커널 버전 확인 : 예) user namespace 사용 시 커널 6.5 이상 필요 - Docs
- containerd 버전 조사 : 예) user namespace 에 대한 CRI 지원 시 containerd v2.0 및 runc v1.2 이상 필요 - Docs
- K8S 호환 버전 확인 - Docs
- CSI : Skip…
- 애플리케이션 요구사항 검토… dprecated api 없는 지 확인
1️⃣ 사전 준비
- (옵션) 각 작업 별 상세 명령 실행 및 스크립트 작성, 작업 중단 실패 시 롤백 명령/스크립트 작성
- 모니터링 설정
- (1) ETCD 백업
- (2) CNI(cilium) 업그레이드
2️⃣ CP 노드 순차 업그레이드 : 1.28 → 1.29 → 1.30
- 마스터 노드 1대씩 작업 진행 1.28 → 1.29
- (3) Ubuntu OS(kernel) 업그레이드 → 재부팅 (*커널 버전 업그레이드 필요 시)
- (4) containerd 업그레이드 → containerd 서비스 재시작
- (5) kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 마스터 노드 1대씩 작업 진행 1.29 → 1.30
- (5) kubeadm 업그레이드 → kubelet/kubectl 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 CP 노드 상태 확인
3️⃣ DP 노드 순차 업그레이드 : 1.28 → 1.29 → 1.30
- 워커 노드 1대씩 작업 진행 1.28 → 1.29
- (6) 작업 노드 drain 설정 후 파드 Evicted 확인, 서비스 중단 여부 모니터링 확인
- (7) Ubuntu OS(kernel) 업그레이드 → 재부팅
- (8) containerd 업그레이드 → containerd 서비스 재시작
- (9) kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 워커 노드 1대씩 작업 진행 1.29 → 1.30
- (9) kubeadm 업그레이드 → kubelet 업그레이드 설치 → kubelet 재시작
- 작업 완료 후 DP 노드 상태 확인 ⇒ (10) 작업 노드 uncordon 설정 후 다시 상태 확인
4️⃣ K8S 관련 전체적인 동작 1차 점검
- 애플리케이션 파드 동작 확인 등
- 서비스 헬스체크 및 성능지표 확인
사실 EKS 같은 관리형 서비스가 아닌 바닐라쿠버네티스 환경에서 업그레이드를 진행하는 것은 다소 복잡하고 어려운 과정입니다. 또한 실제 상용중인 서비스의 경우 관리 포인트가 많은 만큼 장애 발생 가능성과 작업에 수많은 에너지가 소요되기 마련입니다. 이러한 피로도와 cost 때문에 EKS를 고려하는 사용자가 늘어나고 있는 것 같습니다.
EKS Upgrade
EKS Upgrade 의 장점
EKS 환경에서 쿠버네티스 업그레이드 하는 것은 다음과 같은 장점이 있습니다.
- Control Plane 자동 관리: EKS는 마스터 노드(Control Plane)를 AWS에서 자동으로 관리하고 업그레이드해주기 때문에, 사용자는 워커 노드(Data Plane)에만 집중하면 되어 운영 부담과 실수 가능성을 줄일 수 있습니다.
- 안정성과 검증된 신뢰성: AWS는 다양한 테스트와 검증 과정을 거친 후에 업그레이드 가능한 버전을 제공합니다. 이를 통해 사용자는 별도의 복잡한 테스트 없이도 비교적 안전하게 클러스터를 업그레이드할 수 있습니다.
- 업그레이드 도구 및 자동화 생태계 지원: eksctl, Managed Node Group, Blue/Green 업그레이드 전략 등 다양한 도구와 기능이 제공되어 업그레이드 절차를 자동화하거나 쉽게 관리할 수 있는 환경이 마련되어 있습니다.
EKS 책임 모델
EKS는 compute type에 따라 조금씩 책임모델이 상이합니다. 공통적으로 컨트롤 플레인은 AWS가 담당하는 것을 알 수 있습니다.
🔷 EKS Fargate
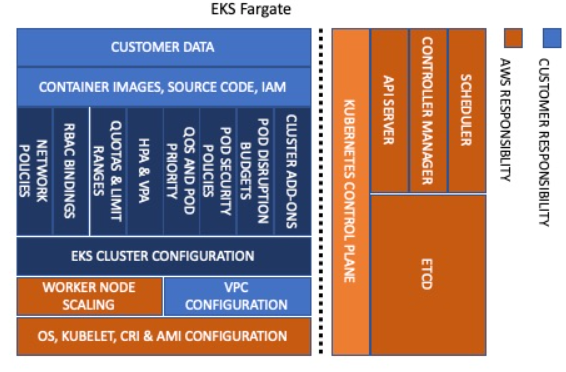
- 가장 관리 부담이 적은 방식
- 워커 노드를 직접 관리하지 않아도 되므로 보안 리스크 최소화
- daemonset 사용이 제한적이며, 커널 설정이나 호스트 네트워크 접근 등은 불가능
🔷 Self Managed

- 가장 유연하고 자유롭지만, 가장 높은 관리 복잡도
- 커스터마이징이 많을수록 유지보수 리스크도 커짐
🔷 Managed Node Group

- 유연성과 자동화 사이의 균형
- 관리 노드를 사용하되, AWS가 일부 자동화(예: 노드 그룹 업그레이드, 롤링 업데이트) 제공
- Fargate보다는 제어권이 많지만, 여전히 AWS가 기본 노드 운영 책임을 가져감
이처럼 사용자의 필요에 맞는 compute type을 선택하고 보다 데이터플레인의 영역만 신경쓰면 되기 때문에 업그레이드 과정 또한 수월할 수 있습니다.
EKS Release cycle
EKS는 기본적으로 K8S release cycle에 따라 최대 14개월 정도의 표준 지원을 제공하고 이 외에 추가적으로 확장된 지원을 12개월 동안 지원 합니다. 확장된 지원 기간이 끝나면 클러스터는 다음 단계로 한단계 자동으로 업그레이드 되므로 강제 업그레이드가 적용되기 전에 반드시 업그레이드를 수행하여야 예기치 못한 상황을 방지할 수 있습니다. 또한 클러스터 업그레이드의 중요성은 위에서 말씀 드린 것 처럼 매우 중요한 부분이기 때문에 표준지원을 넘기지 않는 선에서 업그레이드를 주기적으로 수행하는 것이 바람직합니다.

확장 지원 기간 동안 Kubernetes 버전을 실행하는 클러스터의 가격은 2024년 4월 1일부터 클러스터당 시간당 총 $0.60의 요금이 부과되며, 비용 표준 지원은 변경되지 않습니다(클러스터당 시간당 $0.10).
| Support type | Duration | Price (per cluster per hour) |
|---|---|---|
| Standard | 14 months starting from the date a version is generally available on Amazon EKS | $0.10 |
| Extended | 12 months starting from the date a version reaches the end of standard support in Amazon EKS | $0.60 |
실습 환경 구성
실습 내용
이번 실습은 EKS 환경에서 다음과 같이 두 가지 업그레이드 전략을 사용합니다.
- 단일 클러스터에서 roll out 하며 업그레이드 하는 In-place cluster upgrade 방식
- 클러스터 버전이 업그레이드된 클러스터를 생성하여 기존 클러스터에서 트래픽을 신규 클러스터로 스위칭하는 Blue Green 방식
이 두 가지 방식을 진행해보면서 각각의 차이점과 장단점에 대해서 살펴보겠습니다.
실습 환경 개요
이번 실습은 AWS Workshop을 통해 진행되기 때문에 별도로 실습환경을 구축하는 단계는 포함되지 않습니다. 미리 구성된 인프라와 브라우저 IDE 의 작업 환경을 통해 실습을 진행하였습니다.
실습 환경의 대략적인 구성은 다음과 같습니다.
- 클러스터 버전: 1.25
- 커널: 5.10.234
- OS: Amazon Linux2
- containerd: 1.7.25
- terraform 환경
- S3 backend 사용
- 해당 실습을 위한 인프라 구성
- eksctl, kubernetes 등 쿠버네티스 관리 도구 설치
- eks 조작을 위한 관리서버 (IDE 서버)
- 애플리케이션 소스코드 : AWS Codecommit
작업 환경 구성 - k8s 도구 설치
실습 편의를 위해 k8s 관리 도구 및 개발 환경을 세팅합니다.
kube-ops-view 설치
Helm 으로 kube-ops-view를 설치 후 외부에서 kube-ops-view 접근을 위한 NLB를 생성합니다.
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm repo update
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --namespace kube-system
#
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-type: external
labels:
app.kubernetes.io/instance: kube-ops-view
app.kubernetes.io/name: kube-ops-view
name: kube-ops-view-nlb
namespace: kube-system
spec:
type: LoadBalancer
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/instance: kube-ops-view
app.kubernetes.io/name: kube-ops-view
EOF
# kube-ops-view 접속 URL 확인 (1.5, 1.3 배율)
kubectl get svc -n kube-system kube-ops-view-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "KUBE-OPS-VIEW URL = http://"$1"/#scale=1.5"}'
kubectl get svc -n kube-system kube-ops-view-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "KUBE-OPS-VIEW URL = http://"$1"/#scale=1.3"}'
krew 설치
Krew는 kubectl 플러그인을 설치하고 관리할 수 있도록 도와주는 패키지 매니저입니다.
이를 통해 다양한 커뮤니티 플러그인을 손쉽게 설치하여 kubectl의 기능을 확장할 수 있습니다.
# 설치
(
set -x; cd "$(mktemp -d)" &&
OS="$(uname | tr '[:upper:]' '[:lower:]')" &&
ARCH="$(uname -m | sed -e 's/x86_64/amd64/' -e 's/\(arm\)\(64\)\?.*/\1\2/' -e 's/aarch64$/arm64/')" &&
KREW="krew-${OS}_${ARCH}" &&
curl -fsSLO "https://github.com/kubernetes-sigs/krew/releases/latest/download/${KREW}.tar.gz" &&
tar zxvf "${KREW}.tar.gz" &&
./"${KREW}" install krew
)
# PATH
export PATH="${KREW_ROOT:-$HOME/.krew}/bin:$PATH"
vi ~/.bashrc
-----------
export PATH="${KREW_ROOT:-$HOME/.krew}/bin:$PATH"
-----------
# 플러그인 설치
kubectl krew install ctx ns df-pv get-all neat stern oomd whoami rbac-tool rolesum
kubectl krew list
kubectl df-pv 명령어를 통해 PV의 사용량을 쉽게 확인합니다.

kubectl whoami 을 사용하면 여러 클러스터나 사용자 계정을 오가며 작업할 때 유용합니다.

EKS node viewer 설치
터미널에서 node관련 시스템 메트릭을 시각적으로 확인할 수 있습니다.
wget -O eks-node-viewer https://github.com/awslabs/eks-node-viewer/releases/download/v**0.7.1**/eks-node-viewer_Linux_x86_64
chmod +x eks-node-viewer
sudo mv -v eks-node-viewer /usr/local/bin
k9s 설치
k9s는 터미널 기반의 Kubernetes 대시보드로, kubectl 명령어 없이도 클러스터 리소스를 실시간으로 보고 조작할 수 있게 해주는 도구입니다.
curl -sS https://webinstall.dev/k9s | bash
k9s version실습 환경 확인 - 클러스터
클러스터 확인
eksctl get cluster

클러스터 버전 확인
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq -r .cluster.version

해당 클러스터는 1.25로 다소 낮은 버전을 사용중 인것으로 확인 됩니다.
노드그룹 확인
eksctl get nodegroup --cluster $CLUSTER_NAME

Fargate 프로파일 확인
eksctl get fargateprofile --cluster $CLUSTER_NAME

노드 주요 정보 확인(라벨)
kubectl get node --label-columns=eks.amazonaws.com/capacityType,node.kubernetes.io/lifecycle,karpenter.sh/capacity-type,eks.amazonaws.com/compute-type

노드 유형을 살펴보면 다음과 같이 다양하게 구성되어 있는 것을 확인 가능합니다.
- compute-type이 fargate인 노드 한 대
- compute-type이 spot인 노드 한 대
- capacity type이 온디맨드인 노드 세 대
- 그 외 self-managed 노드 2대 (카펜터로 관리도되는 노드는 self-managed로 분류됩니다.)
노드 그룹 확인
kubectl get node -L eks.amazonaws.com/nodegroup,karpenter.sh/nodepool

노드 그룹을 살펴보면 blue-mng와 initial 두 그룹으로 구성되어 있고 위 capacity type을 보면 온디맨드 형태인걸 알 수 있습니다.
nodeclaims 확인
kubectl get nodeclaims


카펜터가 defualt 노드풀을 참조하여 10.0.47.3 인스턴스가 생성된 것을 확인할 수 있습니다.
실습 환경 확인 - 워크로드
helm 으로 배포된 리스트를 확인합니다.
helm list -A

argocd 로 배포된 리소스를 확인합니다.
kubectl get applications -n argocd

실습 샘플 애플리케이션 아키텍처
이번 실습에서는 MSA 아키텍처로 구성된 쇼핑몰의 일반적인 아키텍처 형태를 채택하였습니다.

작업 환경 구성 - 코드 repo 연동
소스코드 저장소로 사용 중인 codecommit을 연동합니다.
cd ~/environment
git clone codecommit::${REGION}://eks-gitops-repo
sudo yum install tree -y
tree eks-gitops-repo/ -L 2
작업 환경 구성 - argocd 서버 접속

앱 배포 관리를 위해 argocd 서버에 접속하여 애플리케이션 배포 형상을 확인합니다.
secrets 오브젝트에 저장된 argocd 초기 패스워드를 호출하여 저장합니다.
export ARGOCD_SERVER=$(kubectl get svc argo-cd-argocd-server -n argocd -o json | jq --raw-output '.status.loadBalancer.ingress[0].hostname')
echo "ArgoCD URL: http://${ARGOCD_SERVER}"
# admin 비밀번호 확인
export ARGOCD_PWD=$(kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d)
echo "Password: ${ARGOCD_PWD}"해당 패스워드를 사용하여 admin / pw 로 로그인합니다.
초기 접속화면은 다음과 같습니다.

위와 같은 애플리케이션은 argo 서버 뿐만 아니라 cli에서도 다음과 같은 명령어를 통해 확인해볼 수 있습니다.
#
**argocd login ${ARGOCD_SERVER} --username ${ARGOCD_USER} --password ${ARGOCD_PWD} --insecure --skip-test-tls --grpc-web**
'admin:login' logged in successfully
Context 'k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com' updated
#
**argocd repo list**
TYPE NAME REPO INSECURE OCI LFS CREDS STATUS MESSAGE PROJECT
git https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo false false false true Successful
#
**argocd app list**
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/apps https://kubernetes.default.svc default Synced Healthy Auto <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo app-of-apps
argocd/assets https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/assets main
argocd/carts https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/carts main
argocd/catalog https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/catalog main
argocd/checkout https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/checkout main
argocd/karpenter https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/karpenter main
argocd/orders https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/orders main
argocd/other https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/other main
argocd/rabbitmq https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/rabbitmq main
argocd/ui https://kubernetes.default.svc default OutOfSync Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/ui main
**argocd app get apps**
Name: argocd/apps
Project: default
Server: https://kubernetes.default.svc
Namespace:
URL: https://k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com/applications/apps
Source:
- Repo: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
Target:
Path: app-of-apps
SyncWindow: Sync Allowed
Sync Policy: Automated
Sync Status: Synced to (acc257a)
Health Status: Healthy
GROUP KIND NAMESPACE NAME STATUS HEALTH HOOK MESSAGE
argoproj.io Application argocd karpenter Synced application.argoproj.io/karpenter created
argoproj.io Application argocd carts Synced application.argoproj.io/carts created
argoproj.io Application argocd assets Synced application.argoproj.io/assets created
argoproj.io Application argocd catalog Synced application.argoproj.io/catalog created
argoproj.io Application argocd checkout Synced application.argoproj.io/checkout created
argoproj.io Application argocd rabbitmq Synced application.argoproj.io/rabbitmq created
argoproj.io Application argocd other Synced application.argoproj.io/other created
argoproj.io Application argocd ui Synced application.argoproj.io/ui created
argoproj.io Application argocd orders Synced application.argoproj.io/orders created
**argocd app get carts**
Name: argocd/carts
Project: default
Server: https://kubernetes.default.svc
Namespace:
URL: https://k8s-argocd-argocdar-eb7166e616-ed2069d8c15177c9.elb.us-west-2.amazonaws.com/applications/carts
Source:
- Repo: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
Target: main
Path: apps/carts
SyncWindow: Sync Allowed
Sync Policy: Automated (Prune)
Sync Status: Synced to main (acc257a)
Health Status: Healthy
GROUP KIND NAMESPACE NAME STATUS HEALTH HOOK MESSAGE
Namespace carts Synced namespace/carts created
ServiceAccount carts carts Synced serviceaccount/carts created
ConfigMap carts carts Synced configmap/carts created
Service carts carts-dynamodb Synced Healthy service/carts-dynamodb created
Service carts carts Synced Healthy service/carts created
apps Deployment carts carts Synced Healthy deployment.apps/carts created
apps Deployment carts carts-dynamodb Synced Healthy deployment.apps/carts-dynamodb created
#
**argocd app get carts -o yaml**
...
spec:
destination:
server: https://kubernetes.default.svc
ignoreDifferences:
- group: apps
jsonPointers:
- /spec/replicas
- /metadata/annotations/deployment.kubernetes.io/revision
kind: Deployment
- group: autoscaling
jsonPointers:
- /status
kind: HorizontalPodAutoscaler
project: default
source:
path: apps/carts
repoURL: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- RespectIgnoreDifferences=true
...
**argocd app get ui -o yaml**
...
spec:
destination:
server: https://kubernetes.default.svc
ignoreDifferences:
- group: apps
jsonPointers:
- /spec/replicas
- /metadata/annotations/deployment.kubernetes.io/revision
kind: Deployment
- group: autoscaling
jsonPointers:
- /status
kind: HorizontalPodAutoscaler
project: default
source:
path: apps/ui
repoURL: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- RespectIgnoreDifferences=true
...
argocd app list

작업 환경 구성 - UI 접속 확인을 위한 NLB 구성
실제 쇼핑몰 애플리케이션에 접속하여 상태를 확인하기 위해 해당 서비스에 진입할 NLB를 구성하여 줍니다.
#
**cat << EOF > ~/environment/eks-gitops-repo/apps/ui/service-nlb.yaml**
apiVersion: v1
kind: **Service**
metadata:
annotations:
service.beta.kubernetes.io/**aws-load-balancer-nlb-target-type: ip**
service.beta.kubernetes.io/**aws-load-balancer-scheme: internet-facing**
service.beta.kubernetes.io/**aws-load-balancer-type: external**
labels:
app.kubernetes.io/instance: ui
app.kubernetes.io/name: ui
**name: ui-nlb
namespace: ui**
spec:
**type: LoadBalancer**
ports:
- name: http
**port: 80**
protocol: TCP
**targetPort: 8080**
selector:
app.kubernetes.io/instance: ui
app.kubernetes.io/name: ui
**EOF**
**cat << EOF > ~/environment/eks-gitops-repo/apps/ui/kustomization.yaml**
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: ui
resources:
- namespace.yaml
- configMap.yaml
- serviceAccount.yaml
- service.yaml
- deployment.yaml
- hpa.yaml
**- service-nlb.yaml**
EOF해당 UI URL을 조회하여 접속합니다.
# UI 접속 URL 확인 (1.5, 1.3 배율)
kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "UI URL = http://"$1""}'
웹 콘솔을 통해 다음과 같이 NLB가 생성된 것을 확인할 수 있습니다.

해당 NLB 퍼블릭 도메인으로 접속하면 다음과 같은 쇼핑몰 형태의 웹페이지가 배포된 것을 확인할 수 있습니다.

이는 또한 GitOps로 관리되기 때문에 argo cd에도 UI 애플리케이션이 생성된 것을 확인할 수 있습니다.

이것으로 실습을 진행하기 위한 기본적인 구성 확인 및 준비가 완료되었습니다.
In-place cluster upgrades
사전 준비
쿠버네티스를 업그레이드 하기 전에 일반적으로 사전에 확인해야할 사항들에 대해 체크합니다. 이러한 과정은 블루 그린 업그레이드 전략에서도 마찬가지로 수행합니다.
- Kubernetes와 EKS의 릴리스 노트를 검토하세요.
- 추가 기능의 호환성을 검토하세요. Kubernetes 애드온과 사용자 정의 컨트롤러를 업그레이드하세요.
- 워크로드에서 더 이상 사용되지 않거나 삭제된 API 사용을 식별하고 수정합니다.
- 클러스터를 백업합니다(필요한 경우).
EKS Upgrade Insight
바닐라 쿠버네티스 환경이라면 직접 일일히 업그레이드 전 상세한 내용을 살펴봐야 하겠지만 EKS를 사용하면 EKS 업그레이드 인사이트를 통해서 편리하게 업그레이드 주의사항을 살펴볼수 있습니다.
EKS 업그레이드 인사이트 CLI로 조회하기
aws eks list-insights --filter kubernetesVersions=1.26 --cluster-name $CLUSTER_NAME | jq .
EKS 업그레이드 인사이트 상세 확인
aws eks describe-insight --region $AWS_REGION --id 00d5cb0c-45ef-4a1a-9324-d499a143baad --cluster-name $CLUSTER_NAME | jq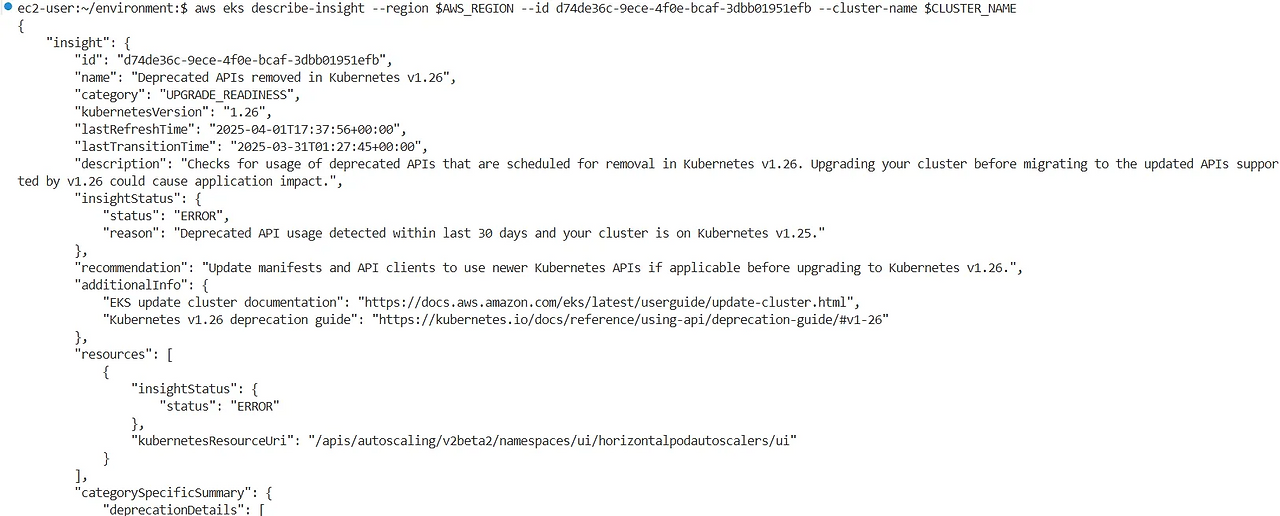
EKS 관리 콘솔로 들어가면 이러한 내용들을 웹페이지에서 확인할 수 있습니다.

upgrade 순서
EKS 에서의 클러스터 업그레이드는 일반적인 k8s 클러스터 업그레이드 순서와 동일합니다. 다만 컨트롤플레인 업그레이드와 기타 업그레이드를 단순히 버튼을 클릭하는 것으로 진행할 수 있다는 것이 가장 큰 장점이자 차이점 입니다.
- Control Plane Upgrade
- Add on Upgrade
- Data Plane Upgrade - 관리형 노드그룹
- Data Plane Upgrade - 카펜터 노드
- Data Plane Upgrade - 셀프 매니지드 노드
- Data Plane Upgrade - 파게이트 노드
- 업그레이드 확인
Control Plane Upgrade
EKS 업그레이드 첫 번째 순서로 컨트롤 플레인을 업그레이드 합니다. 현재 실습에서는 1.25 → 1.26으로의 버전 업그레이드를 수행합니다.
컨트롤플레인을 업그레이드 하는 방법에는 다음과 같은 다양한 옵션이 있습니다.
방법 1 : eksctl
이 명령에서 대상 버전을 지정할 수 있지만 --version에 허용되는 값은 클러스터의 현재 버전 또는 한 버전 더 높은 버전입니다. 즉 두 개 이상의 Kubernetes 버전 업그레이드는 지원되지 않습니다.
eksctl upgrade cluster --name $EKS_CLUSTER_NAME --approve방법 2 : AWS 관리 콘솔
EKS 관리 페이지에서 버튼 하나로 쉽게 업그레이드 가능합니다.

방법 3 : aws cli
클러스터에 관리되는 노드 그룹이 연결되어 있는 경우, 클러스터를 새로운 Kubernetes 버전으로 업데이트하려면 모든 노드 그룹의 Kubernetes 버전이 클러스터의 Kubernetes 버전과 일치해야 합니다.
aws eks update-cluster-version --region ${AWS_REGION} --name $EKS_CLUSTER_NAME --kubernetes-version 1.26예시 출력 화면
{
"update": {
"id": "b5f0ba18-9a87-4450-b5a0-825e6e84496f",
"status": "InProgress",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "PlatformVersion",
"value": "eks.1"
}
],
[...]
"errors": []
}
}
방법 4 : Terraform , 해당 방법으로 실제 업그레이드를 진행합니다
테라폼 코드에서 EKS 버전을 명시하는 값을 변경하여 업그레이드를 실행합니다. 이번 실습에서는 테라폼을 사용하여 클러스터를 관리하므로 테라폼 형상관리를 위해 테라폼을 사용하여 업그레이드를 진행하도록 합니다.
우선 현재 테라폼으로 생성한 리소스에 대한 확인을 해봅니다.
**cd ~/environment/terraform
terraform state list**
컨트롤플레인이 업그레이드 되는지 확인하기 위해 현재 클러스터의 파드 정보를 백업해놓습니다
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.25.txt
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
UI 서버로 요청을 1초마다 보내 헬스체크를 수행합니다.
# IDE-Server 혹은 자신의 PC에서 반복 접속 해두자!
export UI_WEB=$(kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}'/actuator/health/liveness)
curl -s $UI_WEB ; echo
while true; do curl -s $UI_WEB ; date; sleep 1; echo; done
이제 컨트롤플레인을 업그레이드 할 준비가 되었으니 테라폼 init을 통해 플러그인을 설치합니다.
terraform init
테라폼을 통해 컨트롤 플레인 버전을 업그레이드하는 것은 매우 간단합니다. 다음과 같이 variables에서 cluster_version 값을 변경해줍니다.

이제 plan 명령어를 통해 어떠한 리소스에 변화가 발생하는 지 살펴보도록합니다.
terraform plan -no-color > plan-output.txt
plan-output.txt 파일을 열어 plan 출력 내용을 살펴봅니다.

테라폼에서 ~ 기호는 업데이트 예정을 의미합니다. 해당 클러스터가 새로 생성되는 것이 아라 변경 되는것을 확인할 수 있습니다

버전 1.26의 aws_eks_addon_version이 새로 생성되는 것을 확인할 수 있습니다.
이제 실제로 프로비저닝을 위해 apply 해봅니다. 컨트롤플레인 업그레이드는 약 10분 정도 소요됩니다.
terraform apply -auto-approve 
10분뒤에 업그레이드 완료 확인
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq
현재 버전의 모든 파드 리소스를 업그레이드 전에 한 것처럼 파일로 저장합니다.
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.26.txt
1.25 버전과 1.26 클러스터에서 변경된 것이 있는지 확인해봅니다.
**diff 1.26.txt 1.25.txt**
변경된 것없이 기존 워크로드에 영향을 주지않고 업그레이드가 잘 수행된 것을 확인할 수 있습니다.
Cluster insight를 확인해 봅니다.

컨트롤플레인 업그레이드 이후 EKS add-on 과의 버전 호환이 맞지 않아 업그레이드를 권고하는 것을 확인할 수 있습니다.
기타 다른 Skew 사항도 확인해봅니다. 워커노드와 컨트롤플레인의 버전이 일치하지 않아 업그레이드 하라는 권고 사항을 확인할 수 있습니다.

이 외에도 kube-proxy 버전 스큐 이슈가 발생한 것을 확인할 수 있습니다. 이는 계속해서 진행될 실습에서 업그레이드를 수행하여 줍니다.
Add-on 업그레이드
EKS 업그레이드의 일부로 클러스터에 설치된 애드온을 업그레이드해야 합니다. 애드온은 K8s 애플리케이션에 지원 운영 기능을 제공하는 소프트웨어로, 네트워킹, 컴퓨팅 및 스토리지를 위해 클러스터가 기본 AWS 리소스와 상호 작용할 수 있도록 하는 관찰 에이전트 또는 Kubernetes 드라이버와 같은 소프트웨어가 포함됩니다. 애드온 소프트웨어는 일반적으로 Kubernetes 커뮤니티, AWS와 같은 클라우드 공급자 또는 타사 공급업체에서 빌드하고 유지 관리합니다.
Add-on 호환성 확인
❗각 클러스터 버전별로 호환되는 애드온의 버전이 다르므로 이는 업그레이드 시 유의하여 반드시 확인하여야 합니다.
주요 애드온 목록
클러스터 버전별 애드온 호환 버전

eksctl 명령어를 통해서 작업환경에서도 업그레이드 가능한 애드온 버전을 확인할 수 있습니다.
eksctl get addon --cluster $CLUSTER_NAME

테이블 형태로도 확인하려면 다음과 같은 커맨드를 사용합니다. (예시)
# coredns 애드온 확인
aws eks describe-addon-versions --addon-name coredns --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
------------------------------------------
| DescribeAddonVersions |
+-----------------+----------------------+
| DefaultVersion | Version |
+-----------------+----------------------+
| False | v1.9.3-eksbuild.22 |
| False | v1.9.3-eksbuild.21 |
| False | v1.9.3-eksbuild.19 |
| False | v1.9.3-eksbuild.17 |
| False | v1.9.3-eksbuild.15 |
| False | v1.9.3-eksbuild.11 |
| False | v1.9.3-eksbuild.10 |
| False | v1.9.3-eksbuild.9 |
| True | v1.9.3-eksbuild.7 |
| False | v1.9.3-eksbuild.6 |
+-----------------+----------------------+
# kube-proxy 애드온 확인
aws eks describe-addon-versions --addon-name kube-proxy --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
--------------------------------------------
| DescribeAddonVersions |
+-----------------+------------------------+
| DefaultVersion | Version |
+-----------------+------------------------+
| False | v1.26.15-eksbuild.24 |
| False | v1.26.15-eksbuild.19 |
| False | v1.26.15-eksbuild.18 |
| False | v1.26.15-eksbuild.14 |
| False | v1.26.15-eksbuild.10 |
| False | v1.26.15-eksbuild.5 |
| False | v1.26.15-eksbuild.2 |
| False | v1.26.13-eksbuild.2 |
| False | v1.26.11-eksbuild.4 |
| False | v1.26.11-eksbuild.1 |
+-----------------+------------------------+Add-on 버전 업그레이드 하기
현재 실습환경에서 VPC CNI와 EBS CSI Driver 애드온은 최신 버전을 사용중이기 때문에 스킵하고 CoreDNS와 kube-proxy 애드온을 업그레이드 하여 줍니다.
이번에도 마찬가지로 컨트롤플레인을 업그레이드 할 때 처럼 테라폼 코드를 수정하여 업그레이드를 실시합니다.
현재 위에서 확인한 권장 애드온 버전으로 값을 변경합니다.

애드온을 업그레이드 할 때 서비스가 중단되지 않는 지 확인하기 위해 UI 웹 헬스체크를 합니다.
**while true; do curl -s $UI_WEB ; date; kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'; echo ; sleep 2; done**테라폼 플랜으로 리소스 변경사항 확인
cd ~/environment/terraform/
**terraform plan -no-color | tee addon.txt**테라폼 apply로 변경사항 적용. 애드온 업그레이드 같은 경우에는 1~2분 내외로 롤링 업데이트가 완료됩니다.
**terraform apply -auto-approve**
업데이트 확인
**kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'**예시 출력화면
NAME READY STATUS RESTARTS **AGE**
coredns-58cc4d964b-7867s 1/1 Running 0 71s
coredns-58cc4d964b-qb8zc 1/1 Running 0 71s
kube-proxy-2f6nv 1/1 Running 0 61s
kube-proxy-7n8xj 1/1 Running 0 67s
kube-proxy-7p4p2 1/1 Running 0 70s
kube-proxy-g2vvp 1/1 Running 0 54s
kube-proxy-ks4xp 1/1 Running 0 64s
kube-proxy-kxvh5 1/1 Running 0 57s데이터 플레인 업그레이드
컨트롤플레인 → 애드온 → 워커노드 업그레이드를 수행합니다
이번 실습에서는 각 컴퓨팅 유형에 따른 업그레이드 방식의 차이점을 직접 실습해보도록합니다.
- 관리형 노드 그룹(Managed Node Group)
- Karpenter 기반의 자동 노드 프로비저닝
- Fargate 기반 서버리스 노드
관리형 노드 그룹 업그레이드의 경우 완전히 자동화되어 점진적인 롤링 업데이트로 구현됩니다. 새 노드는 EC2 오토 스케일링 그룹에 프로비저닝되고 클러스터에 합류하며 오래된 노드는 코돈 → 드레인 이후 워크로드 파드가 옮겨지면 삭제 됩니다.
데이터 플레인을 업그레이드 할때는 AMI 를 지정하여야 하는데 기본적으로 새 노드는 최신 EKS 최적화 AMI(Amazon Machine Image) 또는 선택적으로 사용자 지정 AMI를 사용합니다.
관리형 노드 그룹 업그레이드 상세 단계
관리형 노드그룹을 업그레이드 하면 다음과 같은 복잡하고 상세한 네 단계의 과정이 자동으로 수행됩니다.
- 설정 단계:
- 노드 그룹과 연결된 자동 스케일링 그룹에 대한 새로운 Amazon EC2 launch template version을 생성합니다.
- The new launch template version은 업데이트에 target AMI 또는 custom launch template version for the update 를 사용합니다.
- Auto Scaling group을 최신 실행 템플릿 버전latest launch template version을 사용하도록 업데이트합니다.
- 노드 그룹에 대한 updateConfig 속성을 사용하여 병렬로 업그레이드할 최대 노드 수를 결정합니다.
- The maximum unavailable has a quota of 100 nodes. 기본값은 1개 노드입니다.
- 확장 단계: 확장 단계에는 다음 단계가 있습니다.
- 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 더 큰 크기로 증가시킵니다. It increments the Auto Scaling Group's maximum size and desired size by the larger of either
- 자동 확장 그룹이 배포된 가용성 영역 수의 최대 2배. Up to twice the number of Availability Zones that the Auto Scaling group is deployed in.
- 업그레이드가 불가능 한 최대 한도입니다. The maximum unavailable of upgrade.
- 자동 확장 그룹을 확장한 후 최신 구성을 사용하는 노드가 노드 그룹에 있고 준비되었는지 확인합니다.
- 그런 다음 노드를 예약 불가능으로 표시하여 새 Pod를 예약하지 않도록 합니다. It then marks nodes as un-schedulable to avoid scheduling new Pods.
- 또한 노드를 node.kubernetes.io/exclude-from-external-load-balancers=true 로 레이블하여 노드를 종료하기 전에 로드 밸런서에서 노드를 제거합니다. It also labels nodes with
node.kubernetes.io/exclude-from-external-load-balancers=trueto remove the nodes from load balancers before terminating the nodes.
- 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 더 큰 크기로 증가시킵니다. It increments the Auto Scaling Group's maximum size and desired size by the larger of either
- 업그레이드 단계*: 업그레이드 단계는 다음과 같은 단계로 구성됩니다.
- 노드 그룹에 대해 구성된 최대 사용 불가능 개수까지 업그레이드가 필요한 노드를 무작위로 선택합니다.
- It randomly selects a node that needs to be upgraded, up to the maximum unavailable configured for the node group.
- 노드에서 Pod를 비웁니다. Pod가 15분 이내에 노드를 떠나지 않고 강제 플래그가 없으면 업그레이드 단계는 PodEvictionFailure 오류
- It drains the Pods from the node. If the Pods don't leave the node within 15 minutes and there's no force flag, the upgrade phase fails with a PodEvictionFailure error. For this scenario, you can apply the force flag with the update-nodegroup-version request to delete the Pods.
- 로 실패합니다 . 이 시나리오에서는 update-nodegroup-version 요청과 함께 강제 플래그를 적용하여 Pod를 삭제할 수 있습니다.
- 모든 Pod가 퇴거된 후 노드를 봉쇄하고 60초 동안 기다립니다. 이는 서비스 컨트롤러가 이 노드에 새로운 요청을 보내지 않고 이 노드를 활성 노드 목록에서 제거하기 위해 수행됩니다.
- It cordons the node after every Pod is evicted and waits for 60 seconds. This is done so that the service controller doesn't send any new requests to this node and removes this node from its list of active nodes.
- cordoned 노드에 대한 자동 확장 그룹에 종료 요청을 보냅니다.
- It sends a termination request to the Auto Scaling Group for the cordoned node.
- 이전 버전의 실행 템플릿을 사용하여 배포된 노드 그룹에 노드가 없을 때까지 이전 업그레이드 단계를 반복합니다.
- It repeats the previous upgrade steps until there are no nodes in the node group that are deployed with the earlier version of the launch template.
- 노드 그룹에 대해 구성된 최대 사용 불가능 개수까지 업그레이드가 필요한 노드를 무작위로 선택합니다.
- 축소 단계: 축소 단계에서는 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 하나씩 감소시켜 업데이트가 시작되기 전 값으로 돌아갑니다.
- 축소 단계는 자동 스케일링 그룹의 최대 크기와 원하는 크기를 하나씩 줄여 업데이트가 시작되기 전의 값으로 돌아갑니다.
Managed Node Group 업그레이드 하기
방법 1 : eksctl
# 우리는 사용 중인 AMI 유형의 Kubernetes 버전에 대한 최신 AMI 릴리스 버전으로 노드 그룹을 업데이트할 수 있습니다.
eksctl upgrade nodegroup --name=managed-ng-1 --cluster=$EKS_CLUSTER_NAME
# 노드 그룹이 클러스터의 Kubernetes 버전에서 이전 Kubernetes 버전인 경우, 다음을 통해 노드 그룹을 클러스터의 Kubernetes 버전과 일치하는 최신 AMI 릴리스 버전으로 업데이트할 수 있습니다.
eksctl upgrade nodegroup --name=managed-ng-1 --cluster=$EKS_CLUSTER_NAME --kubernetes-version=<control plane version>
# 최신 버전 대신 특정 AMI 릴리스 버전으로 업그레이드하려면 다음을 사용합니다.
eksctl upgrade nodegroup --name=managed-ng-1 --cluster=$EKS_CLUSTER_NAME --release-version=<specific AMI Release version>방법 2 : AWS 관리 콘솔
- 업데이트할 노드 그룹이 포함된 클러스터를 선택하세요.
- 하나 이상의 노드 그룹에 사용 가능한 업데이트가 있는 경우 페이지 상단에 사용 가능한 업데이트를 알려주는 상자가 나타납니다. Compute 탭을 선택하면 사용 가능한 업데이트가 있는 노드 그룹의 Node groups 표에서 AMI 릴리스 버전 열에 Update now가 표시됩니다. 노드 그룹을 업데이트하려면 Update now를 선택합니다 .
- 노드 그룹 버전 업데이트 대화 상자에서 다음 옵션을 활성화하거나 비활성화합니다.
- 노드 그룹 버전 업데이트 – 사용자 지정 AMI를 배포했거나 Amazon EKS 최적화 AMI가 현재 클러스터의 최신 버전인 경우 이 옵션을 사용할 수 없습니다.
- 출시 템플릿 버전 변경: 노드 그룹이 사용자 지정 출시 템플릿 없이 배포된 경우 이 옵션을 사용할 수 없습니다.
- 업데이트 전략의 경우 다음 옵션 중 하나를 선택하세요.
- 롤링 업데이트 - 이 옵션은 클러스터의 Pod 중단 예산을 존중합니다. Amazon EKS가 이 노드 그룹에서 실행 중인 Pod를 우아하게 비울 수 없게 하는 Pod 중단 예산 문제가 있는 경우 업데이트가 실패합니다.
- 강제 업데이트 - 이 옵션은 Pod 중단 예산을 존중하지 않습니다. Pod 중단 예산 문제와 관계없이 노드 재시작을 강제로 발생시켜 업데이트가 발생합니다.
방법 3 : Terraform , 해당 방법으로 실제 업그레이드를 진행합니다
이번 실습에서는 관리형 노드그룹을 업그레이드 하면서 동시에 커스텀 AMI를 사용하는 노드그룹과 쿠버네티스 defualt AMI를 사용하는 노드그룹의 업그레이드 차이점에 대해서 확인해보도록 합니다.
이를 위해 기존에 생성되어 있는 관리형 노드그룹(initial) 외에 새로운 관리형 노드그룹(custom)을 생성합니다.
새로운 노드 그룹에서는 사용할 AMI ID를 명시적으로 지정합니다.

해당 AMI ID는 eks optimized ami 로 다음과 같은 명령어를 통해 조회합니다.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.25/amazon-linux-2/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text데이터플레인 리소스가 작성 되어있는 base.tf 코드에 custom 관리형 노드 그룹을 추가합니다.
**custom** = {
instance_types = ["t3.medium"]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
**ami_id = try(var.ami_id)**
enable_bootstrap_user_data = true
}

테라폼 플랜을 통해 리소스 변경 내용을 확인하고 프로비저닝을 진행합니다.
약 2분 정도가 소요됩니다.
terraform plan
terraform apply -auto-approve오토스케일링그룹을 조회하여 관리형 노드그룹이 실제로 생성되었는지 확인합니다.
**while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ;** kubectl get node -L eks.amazonaws.com/nodegroup; echo; **date ;** echo ; **kubectl get node -L eks.amazonaws.com/nodegroup-image** | grep ami**; echo; sleep 1; echo; done**
NAME STATUS ROLES AGE VERSION NODEGROUP
ip-10-0-34-132.us-west-2.compute.internal Ready <none> 78s v1.25.16-eks-59bf375 custom-20250325154855579500000007
NAME STATUS ROLES AGE VERSION NODEGROUP-IMAGE
ip-10-0-34-132.us-west-2.compute.internal Ready <none> 79s v1.25.16-eks-59bf375 ami-0078a0f78fafda978
[
"**default-selfmng**-2025032502302075740000002b",
"eks-blue-mng-20250325023020754500000029-00cae591-7abe-6143-dd33-c720df2700b6",
"eks-custom-20250325154855579500000007-bccae6ff-0a65-c291-f471-404701dd84a8",
"eks-initial-2025032502302076080000002c-30cae591-7ac2-1e9c-2415-19975314b08b"
]조회된 노드에 대한 자세한 정보를 조회합니다.
**kubectl describe node ip-10-0-34-132.us-west-2.compute.internal**
**kubectl get pod -A -owide | grep 10-0-34-132**
웹콘솔에서 새로 생성된 노드그룹을 확인합니다.

이제 데이터플레인의 k8s 버전을 업그레이드 하여 어떤 변화가 발생하는 지 확인해봅니다.
초기 관리 노드그룹에는 정의된 클러스터 버전이 없으며 기본적으로 eks_managed_node_group_defaults에 정의된 클러스터 버전을 사용하도록 설정됩니다.
eks_managed_node_group_defaults 클러스터_버전의 값은 variable.tf 의 변수 mng_cluster_version에 정의되어 있습니다.
variable.tf 에서 변수 mng_cluster_version을 "1.25"에서 "1.26"으로 변경하고 테라폼을 실행합니다.

terraform plan -no-color > plan-output.txt
테라폼 플랜을 하면 다음과 같이 initial 노드 그룹에는 버전 업그레이드 사항이 반영이 되지만 custom 노드 그룹에는 변화가 없는 것을 확인할 수 있습니다.

이는 cusotm노드그룹은 custom AMI를 사용하기 때문에 업그레이드를 수행하기 위해서는 AMI 를 특정하여 지정해주어야 하기 때문입니다. 따라서 다음과 같이 variables.tf의 ami_id변수를 수정하여 줍니다.

이 때 해당 AMI ID는 이전과 같이 다음 명령어를 통해 조회합니다.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/**1.26**/**amazon-linux-2**/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text이제 진짜 플랜 및 어플라이까지 적용합니다. 업그레이드 까지 약 20분 정도 소요가 됩니다.
terraform plan && terraform apply -auto-approve데이터 플레인이 업그레이드 되는 동안 리소스를 모니터링 합니다.
while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
웹 콘솔에서도 업데이트 진행 과정을 확인해봅니다.

업그레이드가 완료되면 다음과 같이 initial 노드그룹 및 custom 노드 그룹의 버전이 동일하게 1.26으로 업데이트 된 것을 확인할 수 있습니다.


업그레이드 완료가 확인 되었으면 Custom AMI 노드그룹의 업그레이드를 확인하기 위해 생성한 custom 노드그룹은 다음 실습을 위해 삭제하여줍니다. 이는 단순하게 terraform 코드를 삭제해주면 됩니다.
❗이때 반드시 테라폼 코드로 삭제해 주어야 형상관리가 되므로 유의합니다.

terraform plan && terraform apply -auto-approveManaged Node Group 업그레이드 하기 - blue/green
위 과정까지 에서 아직 blue-mng 노드 그룹은 업그레이드 하지 않았습니다. 해당 노드그룹을 업그레이드 하면서 데이터플레인 블루/그린 업그레이드 전략을 실습해봅니다.
해당 업그레이드는 다음과 같은 시나리오로 진행됩니다. 기존 노드 그룹(Blue)을 유지한 상태에서 새로운 노드 그룹(Green)을 생성하고, 점진적으로 워크로드를 이전합니다.
blue-mng 노드그룹을 살펴보면 해당 노드는 특정 서비스 만을 담당하도록 되어있는걸 확인할 수 있습니다. 특정 서비스의 파드 (orders)가 taint와 toleration을 통해 특정 노드에만 배포되도록 되어있습니다.
base.tf 파일을 보면 blue-mng 노드그룹의 라벨에 type=OrderMNG 가 설정되어 있는 것을 확인할 수 있습니다.

kubectl 명령어를 통해 해당 노드와 라벨을 조회해봅니다.
**kubectl get nodes -l type=OrdersMNG**
**kubectl get nodes -l type=OrdersMNG -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"**
**kubectl describe node -l type=OrdersMNG**

blue-mng 노드그룹의 상세 노드 정보를 조회해봅니다.

해당 노드는 Type=OrderMNG 라벨이 추가되어있고 Taints가 설정이 되어있는 것을 확인할 수 있습니다.
orders 서비스의 manifest를 조회해봅니다.
cat eks-gitops-repo/apps/orders/deployment.yaml

deployment에 taint와 tolerations를 통해서 해당 파드가 type=OrdersMNG 라벨을 가지는 노드에만 배포되도록 설정한 것을 확인할 수있습니다.
이제 동일한 노드 라벨 설정을 가지고 있는 green-mng 노드그룹을 배포하여 blue-mng에 있는 파드가 옮겨갈 수 있도록 준비를 합니다.
1️⃣ green-mng 노드그룹 배포
green-mng 노드그룹 배포는 기존 처럼 base.tf 파일에 green-mng 코드를 추가하여 배포합니다.
green-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
subnet_ids = [module.vpc.private_subnets[0]]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
}어플라이 합니다.
terraform apply -auto-approve
배포가 완료되면 kubectl 명령어로 노드를 조회합니다.
kubectl get node -l type=OrderMNG -o wide
kubectl get nodes -l type=OrdersMNG -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
# Blue-mng과 Green-mng 관리 그룹 이름을 각각 BLUE_MNG 변수와 GREEN_MNG 변수로 내보냅니다.
export BLUE_MNG=$(aws eks list-nodegroups --cluster-name eksworkshop-eksctl | jq -c .[] | jq -r 'to_entries[] | select( .value| test("blue-mng*")) | .value')
echo $BLUE_MNG
export GREEN_MNG=$(aws eks list-nodegroups --cluster-name eksworkshop-eksctl | jq -c .[] | jq -r 'to_entries[] | select( .value| test("green-mng*")) | .value')
echo $GREEN_MNG
2️⃣ blue-mng 노드그룹 삭제
이제 blue-mng 노드그룹을 제거하여 파드가 green-mng로 옮겨가도록 합니다.
이때 blue-mng를 삭제하려고 하면 pdb가 설정되어 있기 때문에 해당 노드를 삭제하는게 차단됩니다. 따라서 이 문제를 해결하기 위해 레플리카를 2개로 늘립니다.
**kubectl get pdb -n orders**
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
orders-pdb 1 N/A 0 15h
#
cd ~/environment/eks-gitops-repo/
sed -i 's/replicas: 1/replicas: 2/' apps/**orders**/deployment.yaml
git add apps/orders/deployment.yaml
git commit -m "Increase orders replicas 2"
git push
# sync 를 해도 HPA로 무시로 인해 파드는 1개 유지 상태
**argocd app sync orders**
# apps 설정에 deploy replicas 무시 설정되어 있으니, 아래처럼 직접 증가해둘것 (이미 위에서 코드상에는 2로 변경)
# (실행 과정 중) orders 파드가 다른 노드로 옮겨감.. 실행 전에 replicas=2로 실행해두어서 좀 더 안정성 확보
**kubectl scale deploy -n orders orders --replicas 2**
~~~~
이제 pdb(minAvailable=1)를 만족하므로 blue-mng 노드를 삭제할 수 있습니다.
테라폼코드에서 blue-mng 코드를 제거하여 apply 합니다.

**terraform apply -auto-approve**노드가 삭제 되는지 모니터링합니다.
while true; do kubectl get node -l type=OrdersMNG; echo ; kubectl get pod -n orders -l app.kubernetes.io/component=service -owide ; echo ; kubectl get deploy -n orders orders; echo ; kubectl get pdb -n orders; echo ; aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; date ; done

시간이 지난 조금 지난 뒤 확인해보면 기존 node 는 사라지고 두개의 파드가 green노드에 옮겨간 것을 확인할 수 있습니다.

웹콘솔에서도 blue-mng가 삭제됐는지 확인합니다.

이벤트 로그를 확인하면 다음과 같이 cordon 및 drain 후에 remove 되는 과정을 유추할 수 있습니다.
kubectl get events --sort-by='.lastTimestamp' --watch
4m55s Normal NodeNotSchedulable node/ip-10-0-3-199.us-west-2.compute.internal Node ip-10-0-3-199.us-west-2.compute.internal status is now: NodeNotSchedulable
0s Normal NodeNotReady node/ip-10-0-3-199.us-west-2.compute.internal Node ip-10-0-3-199.us-west-2.compute.internal status is now: NodeNotReady
0s Normal DeletingNode node/ip-10-0-3-199.us-west-2.compute.internal Deleting node ip-10-0-3-199.us-west-2.compute.internal because it does not exist in the cloud provider
0s Normal RemovingNode node/ip-10-0-3-199.us-west-2.compute.internal Node ip-10-0-3-199.us-west-2.compute.internal event: Removing Node ip-10-0-3-199.us-west-2.compute.internal from ControllerKarpenter 관리 노드 업그레이드 하기
이번 실습에서는 Karpenter의 동적 노드 프로비저닝 방식에서 노드를 새로 교체하고, 애플리케이션이 새로운 노드로 마이그레이션 되도록하는 실습을 해봅니다.
Karpenter 노드를 업그레이드 하면 기존 노드는 점진적으로 종료되고, 새로운 노드는 수정된 템플릿(AMI 버전 등)을 기반으로 자동 생성됩니다. Karpenter는 자체적으로 스케일링과 노드 수명을 조절하므로 비교적 간단하게 노드 업그레이드를 구현할 수 있습니다.
0️⃣ 카펜터 nodepool, nodeclass 확인
이번 실습에서 karpenter 노드는 checkout 서비스를 담당합니다. 이러한 내용은 카펜터의 노드풀을 상세 조회하여 확인할 수 있습니다.
**kubectl describe nodepool**
Name: default
Namespace:
**Labels**: **argocd**.argoproj.io/instance=karpenter
Annotations: karpenter.sh/nodepool-hash: 12028663807258658692
karpenter.sh/nodepool-hash-version: v2
API Version: **karpenter.sh/v1beta1**
Kind: **NodePool**
Metadata:
Creation Timestamp: 2025-03-25T02:40:15Z
Generation: 1
Resource Version: 6130
UID: 7e081e92-bcfb-4e88-a611-026349b02dd9
**Spec**:
**Disruption**:
**Budgets**:
Nodes: 10%
Consolidation Policy: WhenUnderutilized
Expire After: Never
**Limits**:
Cpu: 100
**Template**:
Metadata:
**Labels:
Env: dev
Team: checkout**
**Spec**:
**Node Class Ref:**
Name: **default**
**Requirements**:
Key: karpenter.k8s.aws/**instance-family**
Operator: In
Values:
c5
m5
m6i
m6a
r4
c4
**** Key: kubernetes.io/**arch**
Operator: In
Values:
**amd64**
Key: karpenter.sh/**capacity-type**
Operator: In
Values:
**on-demand
spot**
Key: kubernetes.io/**os**
Operator: In
Values:
linux
**Taints**:
**Effect: NoSchedule
Key: dedicated
Value: CheckoutApp**
Status:
Resources:
Attachable - Volumes - Aws - Ebs: 25
Cpu: 4
Ephemeral - Storage: 20959212Ki
Memory: 7766420Ki
Pods: 58
Events: <none>또한 nodeclass를 조회해봅니다.
**kubectl describe ec2nodeclass**
Name: default
Namespace:
Labels: argocd.argoproj.io/instance=karpenter
Annotations: karpenter.k8s.aws/ec2nodeclass-hash: 5256777658067331158
karpenter.k8s.aws/ec2nodeclass-hash-version: v2
API Version: **karpenter.k8s.aws/v1beta1**
Kind: **EC2NodeClass**
Metadata:
Creation Timestamp: 2025-03-25T02:40:15Z
**Finalizers:
karpenter.k8s.aws/termination**
Generation: 1
Resource Version: 531983
UID: 1dc1bfc4-adfe-4889-84c5-05d57c7e768d
**Spec**:
Ami Family: AL2
**Ami Selector Terms**:
Id: **ami-0ee947a6f4880da75**
Metadata Options:
Http Endpoint: enabled
httpProtocolIPv6: disabled
Http Put Response Hop Limit: 2
Http Tokens: required
Role: karpenter-eksworkshop-eksctl
**Security Group Selector Terms**:
Tags:
karpenter.sh/discovery: eksworkshop-eksctl
**Subnet Selector Terms**:
Tags:
karpenter.sh/discovery: eksworkshop-eksctl
**Tags**:
Intent: apps
Managed - By: karpenter
Team: checkout
**Status**:
Amis:
**Id**: ami-0ee947a6f4880da75
**Name**: amazon-eks-node-1.25-v20250123
**Requirements**:
Key: kubernetes.io/arch
Operator: In
Values:
amd64
Conditions:
Last Transition Time: 2025-03-25T02:40:16Z
Message:
Reason: Ready
Status: True
Type: Ready
**Instance Profile**: eksworkshop-eksctl_4067990795380418201
**Security Groups**:
Id: sg-009b495bdf238c9dd
Name: eksworkshop-eksctl-node-2025032502202294260000000c
Id: sg-09f8b41af6cadd619
Name: eks-cluster-sg-eksworkshop-eksctl-1769733817
Id: sg-0ef166af090e168d5
Name: eksworkshop-eksctl-cluster-2025032502202287160000000b
**Subnets**:
Id: subnet-047ab61ad85c50486
Zone: us-west-2b
Zone ID: usw2-az1
Id: subnet-01bbd11a892aec6ee
Zone: us-west-2a
Zone ID: usw2-az2
Id: subnet-0aeb12f673d69f7c5
Zone: us-west-2c
Zone ID: usw2-az3
Events: <none>해당 정보를 통해 카펜터 노드는 다음과 같이 관리되는 것을 알 수있습니다.
- 이 노드풀을 사용하면 Spec.Druption.Budgets에 따라 중단 시 10% 노드가 재활용되는 기본 예산이 적용됩니다.
- 이 노드풀에 대해 카펜터를 통해 프로비저닝된 노드에는 Team: Checkout 라벨이 적용되어있으며 Checkout 서비스를 위한 노드임을 확인할 수 있습니다.
- 이 노드풀은 Spec.Template.Spec.NodeClass Ref에 따라 기본 EC2NodeClass를 사용하고 있습니다.
- 이 기본 EC2NodeClass 사양을 사용하여 노드풀은 아미드 ami-03db5eb 228232c943을 사용하여 노드를 프로비저닝하고 있습니다.
1️⃣ checkout 서비스 replica 증설
이제 checkout 서비스 레플리카를 증설하여 노드를 증가시킵니다.
eks-gitops-repo > apps > checkout > deployment.yaml 을 수정하여 레플리카를 늘립니다.

해당 변경사항을 커밋 및 푸시합니다. argo 서버에서sync 버튼을 누르거나 argocd sync 명령어를 사용하여 변경사항을 sync후 배포합니다.
cd ~/environment/eks-gitops-repo
git add apps/checkout/deployment.yaml
git commit -m "scale checkout app"
git push --set-upstream origin main
**argocd app sync checkout**
checkout 파드가 배포된 것을 확인합니다.

노드가 증설된 것을 확인합니다.
**kubectl get nodes -l team=checkout**
NAME STATUS ROLES AGE VERSION
ip-10-0-24-213.us-west-2.compute.internal Ready <none> 62s v1.25.16-eks-59bf375
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 24h v1.25.16-eks-59bf375
1️⃣ Karpenter 리소스 수정
Karpenter는 정기적으로 AMI 드리프트 상태를 감지하기 때문에 이가 변경되면 드리프드된 노드를 제거 대상으로 인식합니다. 따라서 AMI를 변경하면 기존의 노드는 제거되고 새 노드로 파드가 마이그레이션 됩니다.
카펜터의 노드클래스에서 지정된 AMI 버전을 1.25 에서 1.26으로 변경하여 줍니다.

해당 AMI 버전은 다음 명령어를 통해 조회 가능합니다.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/**1.26**/**amazon-linux-2**/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text카펜터는 argocd의 카펜터 앱으로 관리되고 있고 이는 eks-gitops-repo > apps > karpenter 의 경로에서 확인 가능하고 argocd에서도 확인할 수 있습니다.

변경된 사항을 커밋 및 푸시 하고 sync 작업을 동일하게 진행해 줍니다.
cd ~/environment/eks-gitops-repo
git add apps/karpenter/default-ec2nc.yaml apps/karpenter/default-np.yaml
git commit -m "disruption changes"
git push --set-upstream origin main
**argocd app sync karpenter**
업그레이드 과정을 모니터링 합니다.
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
업그레이드가 진행되는 동안 새로운 버전의 노드가 새로 생겨나고 → 기존의 노드 중 하나가 disrupt 대상으로 판정되어 disrupting 상태가 됨 → 해당 노드에서 cordon, drain 을 통해 파드가 다른 노드로 마이그레이션 되고 → 마이그레이션이 완료되면 해당 노드는 삭제가 됩니다. 이는 다음 출력 예제를 통해 살펴볼 수 있습니다.
Wed Mar 26 03:52:39 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-m4bv4 m6a.large us-west-2b ip-10-0-24-213.us-west-2.compute.internal True 15m
default-rpl9w c5.xlarge us-west-2c ip-10-0-39-95.us-west-2.compute.internal True 25h
default-xxf6m c5.xlarge us-west-2c ip-10-0-36-63.us-west-2.compute.internal True 45s
ip-10-0-24-213.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-36-63.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-39-95.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"},
>> {"effect":"NoSchedule",**"key":"karpenter.sh/disruption","value":"disrupting"**}]
NAME STATUS ROLES AGE VERSION
ip-10-0-24-213.us-west-2.compute.internal Ready <none> 14m **v1.25.16**-eks-59bf375
ip-10-0-36-63.us-west-2.compute.internal Ready <none> 22s **v1.26.15**-eks-59bf375
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 25h **v1.25.16**-eks-59bf375
#
Wed Mar 26 03:54:15 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-rngwl m6a.large us-west-2b ip-10-0-21-135.us-west-2.compute.internal True 79s
default-xxf6m c5.xlarge us-west-2c ip-10-0-36-63.us-west-2.compute.internal True 2m22s
ip-10-0-21-135.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-36-63.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME STATUS ROLES AGE VERSION
ip-10-0-21-135.us-west-2.compute.internal Ready <none> 55s **v1.26.15**-eks-59bf375
ip-10-0-36-63.us-west-2.compute.internal Ready <none> 119s **v1.26.15**-eks-59bf375
# 카펜터 동작 로그 확인
**kubectl -n karpenter logs deployment/karpenter -c controller --tail=33 -f**
혹은
**kubectl stern -n karpenter deployment/karpenter -c controller**
#
**kubectl get nodes -l team=checkout**10분 정도 경과되면 노드가 1.26 버전으로 변경되고 파드가 마이그레이션 된것을 확인할 수 있습니다.

Fargate 노드 업그레이드 하기
파게이트의 경우 프로비전 및 노드의 OS 및 커널을 AWS에서 관리하므로 업그레이드도 그만큼 편리합니다. 이번 실습 중 가장 간단한 방법으로 업그레이드가 가능합니다.
asset 서비스 파드는 파게이트 노드에 떠있는 것을 확인할 수 있습니다.
kubectl get pods -n assets -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
assets-7ccc84cb4d-s8wwb 1/1 Running 0 31h 10.0.41.147 fargate-ip-10-0-41-147.us-west-2.compute.internal <none> <none>
# Now, lets describe the node to see its version.
kubectl get node $(kubectl get pods -n assets -o jsonpath='{.items[0].spec.nodeName}') -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
fargate-ip-10-0-41-147.us-west-2.compute.internal Ready <none> 31h v1.25.16-eks-2d5f260 10.0.41.147 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
파게이트는 간단히 rollout 하는 것만으로 자동으로 AWS에서 버전을 클러스터와 동일한 버전으로 업그레이드를 해줍니다. 파게이트는 서버리스 컴퓨팅이기 때문에 이렇게 간단히 업그레이드가 가능합니다.
# **디플로이먼트 재시작 Restart**
**kubectl rollout restart deployment assets -n assets**
# Lets wait for the new pods to become ready.
kubectl wait --for=condition=Ready pods --all -n assets --timeout=180s
# Once the new pods reach ready state, check the version of the new fargate node.
kubectl get pods -n assets -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
assets-569dcdcf9-xwscf 1/1 Running 0 72s 10.0.21.44 **fargate-ip-10-0-21-44**.us-west-2.compute.internal <none> <none>
kubectl get node $(kubectl get pods -n assets -o jsonpath='{.items[0].spec.nodeName}') -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
**fargate**-ip-10-0-21-44.us-west-2.compute.internal Ready <none> 38s **v1.26.15**-eks-2d5f260 10.0.21.44 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
EKS Self-managed 노드 업그레이드 하기
Self-managed Nodes는 사용자가 직접 EC2 기반 노드를 운영하는 방식이기 때문에 사용자가 직접 EC2 인스턴스, AMI, 노드 설정(kubelet, kube-proxy 등)을 해야하고 Managed Node Group이나 Fargate와 달리, 자동 업그레이드는 제공되지 않습니다.
해당 실습에서 self managed 노드는 carts 서비스를 담당하고 있습니다.
kubectl get nodes --show-labels | grep **self-managed**
ip-10-0-26-119.us-west-2.compute.internal Ready <none> 30h **v1.25.16**-eks-59bf375 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m5.large,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=us-west-2,failure-domain.beta.kubernetes.io/zone=us-west-2b,k8s.io/cloud-provider-aws=a94967527effcefb5f5829f529c0a1b9,kubernetes.io/arch=amd64,kubernetes.io/hostname=ip-10-0-26-119.us-west-2.compute.internal,kubernetes.io/os=linux,node.kubernetes.io/instance-type=m5.large,node.kubernetes.io/lifecycle=self-managed,team=carts,topology.ebs.csi.aws.com/zone=us-west-2b,topology.kubernetes.io/region=us-west-2,topology.kubernetes.io/zone=us-west-2b
ip-10-0-6-184.us-west-2.compute.internal Ready <none> 30h **v1.25.16**-eks-59bf375 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m5.large,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=us-west-2,failure-domain.beta.kubernetes.io/zone=us-west-2a,k8s.io/cloud-provider-aws=a94967527effcefb5f5829f529c0a1b9,kubernetes.io/arch=amd64,kubernetes.io/hostname=ip-10-0-6-184.us-west-2.compute.internal,kubernetes.io/os=linux,node.kubernetes.io/instance-type=m5.large,node.kubernetes.io/lifecycle=self-managed,team=carts,topology.ebs.csi.aws.com/zone=us-west-2a,topology.kubernetes.io/region=us-west-2,topology.kubernetes.io/zone=us-west-2a이번 실습에서는 간단하게 AMI 버전을 변경하여 업그레이드 하는 실습을 해봅니다. self-manged 노드그룹의 코드를 수정합니다. base.tf 에서 다음과 같이 코드 내용을 수정합니다.
self_managed_node_groups = {
self-managed-group = {
instance_type = "m5.large"
.
.
.
# Additional configurations
ami_id = **"*ami-086414611b43bb691*" # Replaced the latest AMI ID for EKS 1.26**
subnet_ids = module.vpc.private_subnets
.
.
.
launch_template_use_name_prefix = true
}
}ami_id 는 다음 명령어를 통해 조회합니다.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/**1.26**/**amazon-linux-2**/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text코드 변경 내용을 저장한 후 테라폼을 apply 합니다
**terraform apply -auto-approve**apply가 완료된 후 노드의 버전을 확인합니다.
**kubectl get nodes -l node.kubernetes.io/lifecycle=self-managed**
NAME STATUS ROLES AGE VERSION
ip-10-0-19-69.us-west-2.compute.internal Ready <none> 23m **v1.26.15**-eks-1552ad0
ip-10-0-46-19.us-west-2.compute.internal Ready <none> 28m **v1.26.15**-eks-1552ad0
Blue Green cluster upgrades
Blue green 업그레이드 전략으로는 1.26 → 1.30 으로 한번에 점프하는 업그레이드가 가능합니다. 이는 기존 클러스터를 업그레이드 하는 것이 아니라 신규클러스터 자체를 생성하는 것이기 때문입니다.
이를 다음과 같은 실습을 통해서 확인해봅니다. (실습 특성상 Route 53 가중치 라우팅을 통한 트래픽 조절 내용은 생략되어있습니다.)
신규 Green EKS 클러스터 생성
신규 클러스터에 대한 Terraform 코드 구조를 확인합니다.
versions.tf
terraform {
required_version = ">= 1.3"
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 5.34"
}
helm = {
source = "hashicorp/helm"
version = ">= 2.9"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.20"
}
}
# ## Used for end-to-end testing on project; update to suit your needs
# backend "s3" {
# bucket = "terraform-ssp-github-actions-state"
# region = "us-west-2"
# key = "e2e/karpenter/terraform.tfstate"
# }
}variables.tf
variable "cluster_version" {
description = "EKS cluster version."
type = string
default = "1.30"
}
variable "mng_cluster_version" {
description = "EKS cluster mng version."
type = string
default = "1.30"
}
variable "ami_id" {
description = "EKS AMI ID for node groups"
type = string
default = ""
}
variable "efs_id" {
description = "The ID of the already provisioned EFS Filesystem"
type = string
}
base.tf
provider "aws" {
region = local.region
}
# Required for public ECR where Karpenter artifacts are hosted
provider "aws" {
region = "us-east-1"
alias = "virginia"
}
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
provider "helm" {
kubernetes {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
}
data "aws_partition" "current" {}
data "aws_caller_identity" "current" {}
data "aws_ecrpublic_authorization_token" "token" {
provider = aws.virginia
}
# Data source to reference the existing VPC
data "aws_vpc" "existing_vpc" {
filter {
name = "tag:Name"
values = [local.name]
}
}
data "aws_subnets" "existing_private_subnets" {
filter {
name = "vpc-id"
values = [ data.aws_vpc.existing_vpc.id ]
}
filter {
name = "tag:karpenter.sh/discovery"
values = [local.name]
}
}
data "aws_availability_zones" "available" {}
# tflint-ignore: terraform_unused_declarations
variable "eks_cluster_id" {
description = "EKS cluster name"
type = string
}
variable "aws_region" {
description = "AWS Region"
type = string
}
locals {
name = var.eks_cluster_id
region = var.aws_region
#vpc_cidr = "10.0.0.0/16"
#azs = slice(data.aws_availability_zones.available.names, 0, 3)
tags = {
Blueprint = "${local.name}-gr"
GithubRepo = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
}
################################################################################
# Cluster
################################################################################
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.14"
cluster_name = "${local.name}-gr"
cluster_version = "1.30"
cluster_endpoint_public_access = true
vpc_id = data.aws_vpc.existing_vpc.id
subnet_ids = data.aws_subnets.existing_private_subnets.ids
enable_cluster_creator_admin_permissions = true
eks_managed_node_group_defaults = {
cluster_version = var.mng_cluster_version
}
eks_managed_node_groups = {
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
}
}
# For demonstrating node-termination-handler
self_managed_node_groups = {
default-selfmng = {
instance_type = "m5.large"
min_size = 2
max_size = 4
desired_size = 2
# Additional configurations
subnet_ids = data.aws_subnets.existing_private_subnets.ids
disk_size = 100
# Optional
bootstrap_extra_args = "--kubelet-extra-args '--node-labels=node.kubernetes.io/lifecycle=self-managed,team=carts,type=OrdersMNG'"
# Required for self-managed node groups
create_launch_template = true
launch_template_use_name_prefix = true
}
}
tags = merge(local.tags, {
# NOTE - if creating multiple security groups with this module, only tag the
# security group that Karpenter should utilize with the following tag
# (i.e. - at most, only one security group should have this tag in your account)
"karpenter.sh/discovery" = "${local.name}-gr"
})
}
resource "time_sleep" "wait_60_seconds" {
create_duration = "60s"
depends_on = [module.eks]
}
신규 eks 클러스터를 배포합니다. cluster name은 기존 클러스터에 -gr 접미사를 붙인 이름입니다. 클러스터를 생성하는 데 20분 정도 소요가 됩니다.
cd eksgreen-terraform
terraform init
terraform plan -var efs_id=$EFS_ID
terraform apply -var efs_id=$EFS_ID -auto-approve
eksworkshop-eksctl-gr 이름의 1.30 버전 클러스터가 생성된 것을 확인할 수 있습니다.

이제 하나의 계정에 두 개의 클러스터가 존재합니다. 따라서 작업을 위해서 Kubeconfig를 업데이트 해줍니다.
aws eks --region ${AWS_REGION} update-kubeconfig --name ${EKS_CLUSTER_NAME}-gr --alias **green** && \
kubectl config use-context **green**kubectl config use-context <클러스터이름> 명령어를 통해 필요에따라 컨텍스트를 바꿔가며 관리합니다.
새로 배포된 클러스터의 정보를 확인합니다.
**kubectl get nodes --context green**
NAME STATUS ROLES AGE VERSION
ip-10-0-20-212.us-west-2.compute.internal Ready <none> 21m **v1.30.9**-eks-5d632ec
ip-10-0-21-169.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-35-26.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
ip-10-0-9-126.us-west-2.compute.internal Ready <none> 21m v1.30.9-eks-5d632ec
**helm list -A --kube-context green**
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
argo-cd argocd 1 2025-03-26 11:58:02.453602353 +0000 UTC deployed argo-cd-5.55.0 v2.10.0
aws-efs-csi-driver kube-system 1 2025-03-26 11:58:30.395245866 +0000 UTC deployed aws-efs-csi-driver-2.5.6 1.7.6
aws-load-balancer-controller kube-system 1 2025-03-26 11:58:31.887699595 +0000 UTC deployed aws-load-balancer-controller-1.7.1 v2.7.1
karpenter karpenter 1 2025-03-26 11:58:31.926407743 +0000 UTC deployed karpenter-0.37.0 0.37.0
metrics-server kube-system 1 2025-03-26 11:58:02.447165223 +0000 UTC deployed metrics-server-3.12.0 0.7.0
Stateless 워크로드 마이그레이션
stateless 워크로드는 영구데이터 보관이 필요가 없으므로 데이터 연동 설정 없이 그냥 라우팅 스위칭을 통해 신규 클러스터로 서비스를 이전하면 됩니다. 따라서 애플리케이션소스만 있으면 신규 환경에 해당 서비스를 바로 배포할 수 있습니다.
이러한 과정을 기존의 애플리케이션 리포지토리에 브랜치를 하나 추가해서 구현합니다.
1️⃣ green 브랜치 생성
cd ~/environment/eks-gitops-repo
git switch -c **green**
2️⃣ 카펜터 정보 변경
새로운 그린 클러스터 환경에 맞게끔 카펜터의 노드클래스 AMI를 변경하여 줍니다.
export AL2023_130_AMI=$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.30/amazon-linux-2023/x86_64/standard/recommended/image_id --region ${AWS_REGION} --query "Parameter.Value" --output text)
echo $AL2023_130_AMI
*ami-08eb2eb81143e2902*default-ec2nc.yaml에서 AMI ID, 보안 그룹, IAM 역할 및 기타 세부 정보를 업데이트합니다.
cat << EOF > ~/environment/eks-gitops-repo/apps/karpenter/default-ec2nc.yaml
apiVersion: karpenter.k8s.aws/v1beta1
kind: **EC2NodeClass**
metadata:
name: **default**
spec:
amiFamily: **AL2023**
amiSelectorTerms:
- id: "**${AL2023_130_AMI}**" # Latest EKS 1.30 AMI
role: karpenter-eksworkshop-**eksctl-gr**
securityGroupSelectorTerms:
- **tags**:
karpenter.sh/discovery: eksworkshop-**eksctl-gr**
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl
tags:
intent: apps
managed-by: karpenter
team: checkout
EOF
3️⃣ argocd targetRevision 변경
app-of-apps/values.yaml
**cat app-of-apps/values.yaml**
spec:
destination:
# HIGHLIGHT
server: https://kubernetes.default.svc
source:
# HIGHLIGHT
repoURL: https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo
# HIGHLIGHT
**targetRevision: main**
# HIGHLIGHT
applications:
- name: assets
- name: carts
- name: catalog
- name: checkout
- name: orders
- name: other
- name: rabbitmq
- name: ui
- name: karpenterargocd의 apps-of-apps가 싱크하는 애플리케이션 브랜치를 main에서 green으로 변경하여 줍니다. targetRevision 값 변경후 해당 변경사항을 커밋 및 푸시합니다.
**sed -i 's/targetRevision: main/targetRevision: green/' app-of-apps/values.yaml**
# Commit the change to green branch and push it to the CodeCommit repo.
git add . && git commit -m "1.30 changes"
git push -u origin **green**
4️⃣ argocd 설정
그린클러스터의 argo 서버에 접속합니다.
export ARGOCD_SERVER_GR=$(kubectl get svc argo-cd-argocd-server -n argocd -o json --context **green** | jq --raw-output '.status.loadBalancer.ingress[0].hostname')
echo "ArgoCD URL: http://${ARGOCD_SERVER_GR}"
export ARGOCD_USER_GR="admin"
export ARGOCD_PWD_GR=$(kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" --context green | base64 -d)해당 argocd에 codecommit 리포(eks-gitops-repo) 를 추가합니다.
#
argo_creds=$(aws secretsmanager get-secret-value --secret-id argocd-user-creds --query SecretString --output text)
argocd repo add $(echo $argo_creds | jq -r .url) --username $(echo $argo_creds | jq -r .username) --password $(echo $argo_creds | jq -r .password) --server ${ARGOCD_SERVER_GR}
5️⃣ 애플리케이션 배포
repository가 연동되었으면 마지막으로 애플리케이션을 배포합니다.
#
argocd app create apps --repo $(echo $argo_creds | jq -r .url) --path app-of-apps \
--dest-server https://kubernetes.default.svc --sync-policy automated --revision green --server ${ARGOCD_SERVER_GR}
#
argocd app list --server ${ARGOCD_SERVER_GR}
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/apps https://kubernetes.default.svc default Synced Healthy Auto <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo app-of-apps green
argocd/assets https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/assets green
argocd/carts https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/carts green
argocd/catalog https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/catalog green
argocd/checkout https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/checkout green
argocd/karpenter https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/karpenter green
argocd/orders https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/orders green
argocd/other https://kubernetes.default.svc default Synced Healthy Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/other green
argocd/rabbitmq https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/rabbitmq green
argocd/ui https://kubernetes.default.svc default Synced Progressing Auto-Prune <none> https://git-codecommit.us-west-2.amazonaws.com/v1/repos/eks-gitops-repo apps/ui green
아르고 서버에서 애플리케이션 배포를 확인합니다.

마무리
지금까지 다양한 유형의 EKS 업그레이드 방식을 실습을 통해서 살펴보았습니다. 바닐라쿠버네티스 환경에서 업그레이드를 진행하는 것은 작업자로 하여금 많은 부담을 주는데 EKS클러스터 업그레이드는 굉장히 편리한것 같다고 느꼈고 AWS를 사용중이라면 VM위에 자체 k8s 클러스터를 구성하는 것보다는 EKS를 적극 활용하는 것이 좋을 것 같다고 느꼈습니다.
'AWS > EKS' 카테고리의 다른 글
| K8s 시크릿 관리 with Vault (0) | 2025.04.13 |
|---|---|
| K8S 환경에서 CI/CD 구축하기 - 2 (0) | 2025.03.30 |
| K8S 환경에서 CI/CD 구축하기 - 1 (0) | 2025.03.30 |
| EKS Auto Mode (0) | 2025.03.23 |
| EKS Security - OPA 로 정책 적용하기 (0) | 2025.03.16 |



